Kaynak
Copyleaks'nin Doğruluğunun Değerlendirilmesi Yapay Zeka Dedektörü
Adım Adım Metodoloji
Test tarihi: 25 Mayıs 2024
Test edilen model: V5
AI Dedektörünün özellikleri konusunda tamamen şeffaf olmanın her zamankinden daha önemli olduğuna inanıyoruz. Sorumlu kullanım ve benimsenmeyi sağlamak için doğruluk, yanlış pozitif ve yanlış negatif oranları, iyileştirilecek alanlar ve daha fazlası. Bu kapsamlı analiz, AI Dedektörümüzün V5 model test metodolojisi etrafında tam şeffaflık sağlamayı amaçlamaktadır.
Metodoloji
Copyleaks Veri Bilimi ve QA ekipleri, tarafsız ve doğru sonuçlar sağlamak için bağımsız olarak testler gerçekleştirdi. Test verileri, eğitim verilerinden farklıydı ve daha önce AI tespiti için AI Dedektörüne gönderilen hiçbir içeriği içermiyordu.
Test verileri, doğrulanmış veri kümelerinden elde edilen insan tarafından yazılan metinlerden ve çeşitli yapay zeka modellerinden yapay zeka tarafından oluşturulan metinlerden oluşuyordu. Test Copyleaks API ile gerçekleştirildi.
Metrikler
Metrikler, gerçek pozitif oranları (TPR) ve hatalı pozitif oranları (FPR) inceleyen ROC-AUC'ye (Alıcı Çalışma Karakteristiği - Eğri Altındaki Alan) ek olarak doğru ve yanlış metin tanımlama oranına dayalı genel doğruluğu içerir. Ek ölçümler arasında F1 puanı, gerçek negatif oran (TNR), doğruluk ve karışıklık matrisleri bulunur.
Sonuçlar
Testler, Yapay Zeka Dedektörünün, düşük yanlış pozitif oranını korurken, insan tarafından yazılan metin ile yapay zeka tarafından oluşturulan metin arasında ayrım yapmak için yüksek bir algılama doğruluğu sergilediğini doğruladı.
Değerlendirme süreci
Çift departmanlı bir sistem kullanarak değerlendirme sürecimizi en üst düzeyde kalite, standart ve güvenilirlik sağlayacak şekilde tasarladık. Modeli değerlendiren iki bağımsız departmanımız var: veri bilimi ve QA ekipleri. Her departman kendi değerlendirme verileri ve araçlarıyla bağımsız olarak çalışır ve diğerinin değerlendirme sürecine erişimi yoktur. Bu ayırma, modelimizin performansının olası tüm boyutlarını yakalarken, değerlendirme sonuçlarının tarafsız, objektif ve doğru olmasını sağlar. Ayrıca, test verilerinin eğitim verilerinden ayrıldığını ve modellerimizi yalnızca geçmişte görmedikleri yeni veriler üzerinde test ettiğimizi unutmamak önemlidir.
Metodoloji
Copyleaks' QA ve Veri Bilimi ekipleri bağımsız olarak çeşitli test veri kümelerini topladı. Her test veri seti sınırlı sayıda metinden oluşur. Her veri kümesinin beklenen etiketi (belirli bir metnin bir insan tarafından mı yoksa yapay zeka tarafından mı yazıldığını gösteren bir işaretleyici) verinin kaynağına göre belirlenir. İnsan metinleri, modern üretken yapay zeka sistemlerinin ortaya çıkmasından önce yayınlanan metinlerden veya daha sonra ekip tarafından tekrar doğrulanan diğer güvenilir kaynaklar tarafından toplandı. Yapay zeka tarafından oluşturulan metinler, çeşitli üretken yapay zeka modelleri ve teknikleri kullanılarak oluşturuldu.
Testler Copyleaks API'sine karşı gerçekleştirildi. Hedef etikete dayalı olarak her metin için API çıktısının doğru olup olmadığını kontrol ettik ve ardından karışıklık matrisini hesaplamak için puanları topladık.
Sonuçlar: Veri Bilimi Ekibi
Veri Bilimi ekibi aşağıdaki bağımsız testi gerçekleştirdi:
- Metinlerin dili İngilizceydi ve çeşitli LLM'lerden toplamda 250.030 insan tarafından yazılan metin ve 123.244 yapay zeka tarafından oluşturulan metin test edildi.
- Metin uzunlukları farklılık gösterir ancak veri kümeleri yalnızca ürünümüzün kabul ettiği minimum değer olan 350 karakterden daha uzun metinleri içerir.
Değerlendirme Metrikleri
Bu metin sınıflandırma görevinde kullanılan ölçümler şunlardır:
1. Karışıklık matrisi: TP (gerçek pozitifler), FP (yanlış pozitifler), TN (gerçek negatifler) ve FN'yi (yanlış negatifler) gösteren bir tablo.
2. Doğruluk: gerçek sonuçların (hem gerçek pozitifler hem de gerçek negatifler) oranı toplam metin sayısı kontrol edildi.

3. TNR: Doğru negatif tahminlerin oranı tüm olumsuz tahminler.

Yapay zeka tespiti bağlamında TNR, modelin insan metinleri üzerindeki doğruluğudur.
4. TPR (Geri Çağırma olarak da bilinir): Gerçek pozitif sonuçların oranı tüm gerçek tahminler.

Yapay zeka tespiti bağlamında TPR, modelin yapay zeka tarafından oluşturulan metinlerdeki doğruluğudur.
5. F-beta Puanı: Kesinlik ve geri çağırma arasındaki ağırlıklı harmonik ortalama, kesinliği daha fazla tercih eder (daha düşük bir Yanlış Pozitif Oranını tercih etmek istediğimiz için).

6. ROC-AUC: Değerlendirilmesi Pazarlıksız TPR ve FPR arasında.

Birleşik Yapay Zeka ve İnsan Veri Kümeleri
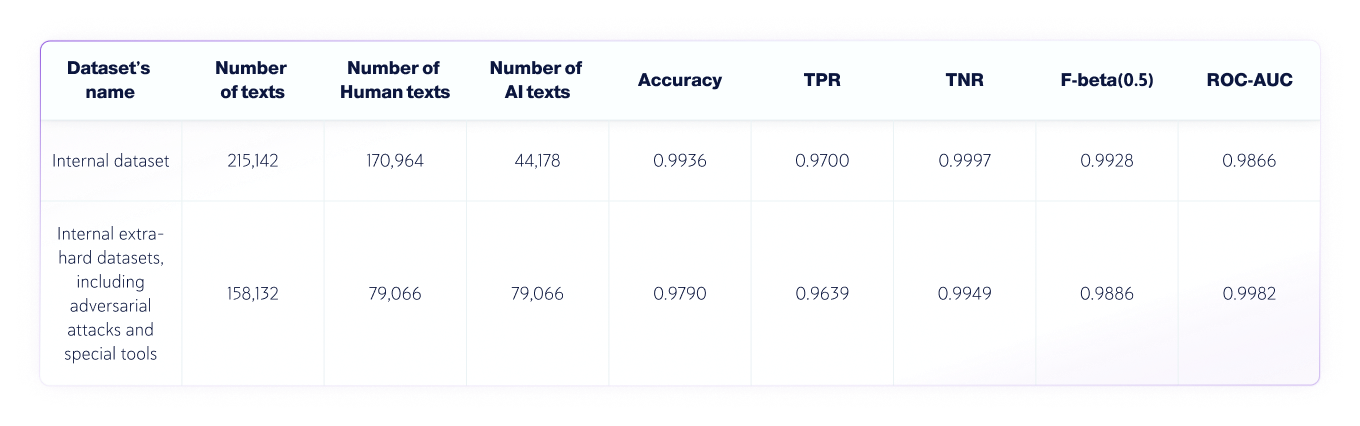
Sonuçlar: Kalite Güvence Ekibi
QA ekibi aşağıdaki bağımsız testi gerçekleştirdi:
- Metnin dili İngilizceydi ve çeşitli LLM'lerden insan tarafından yazılan 320.000 metin ve yapay zeka tarafından oluşturulan 162.500 metin toplamda test edildi.
- Metin uzunlukları farklılık gösterir ancak veri kümeleri yalnızca ürünümüzün kabul ettiği minimum değer olan 350 karakterden daha uzun metinleri içerir.
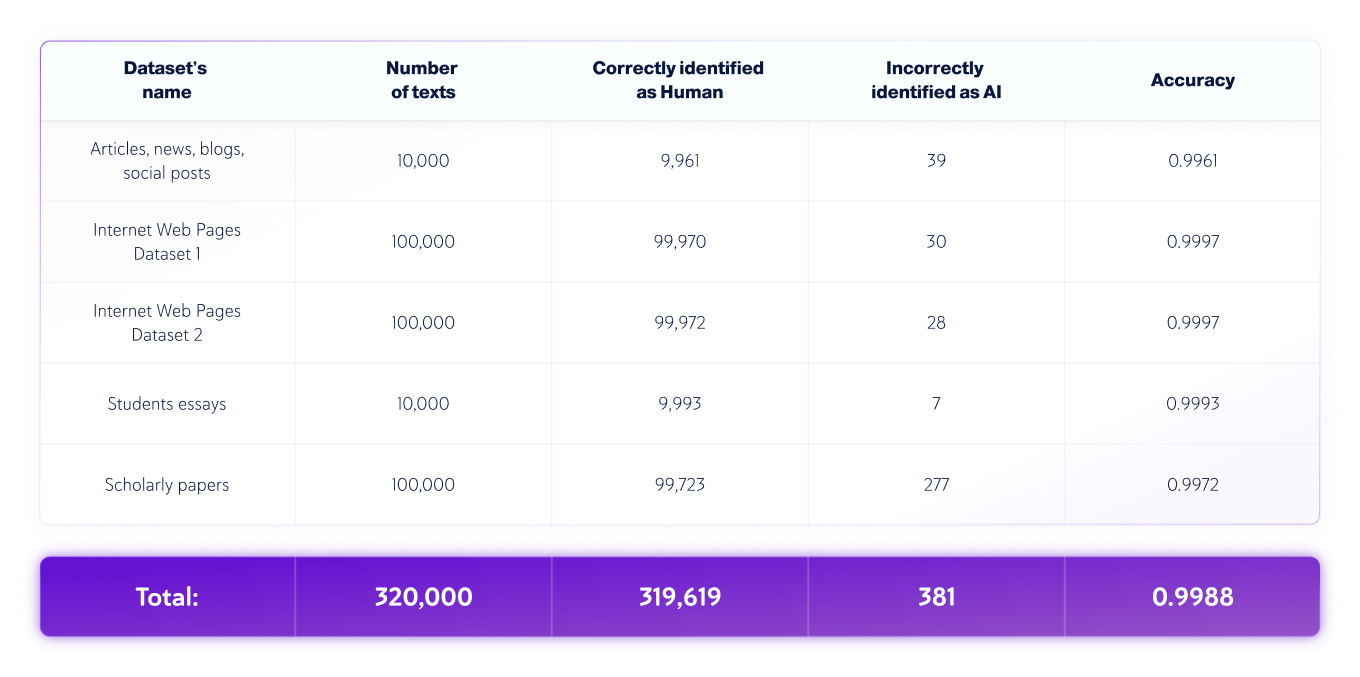
Yalnızca İnsanlara Yönelik Veri Kümeleri
Yalnızca Yapay Zeka Veri Kümeleri
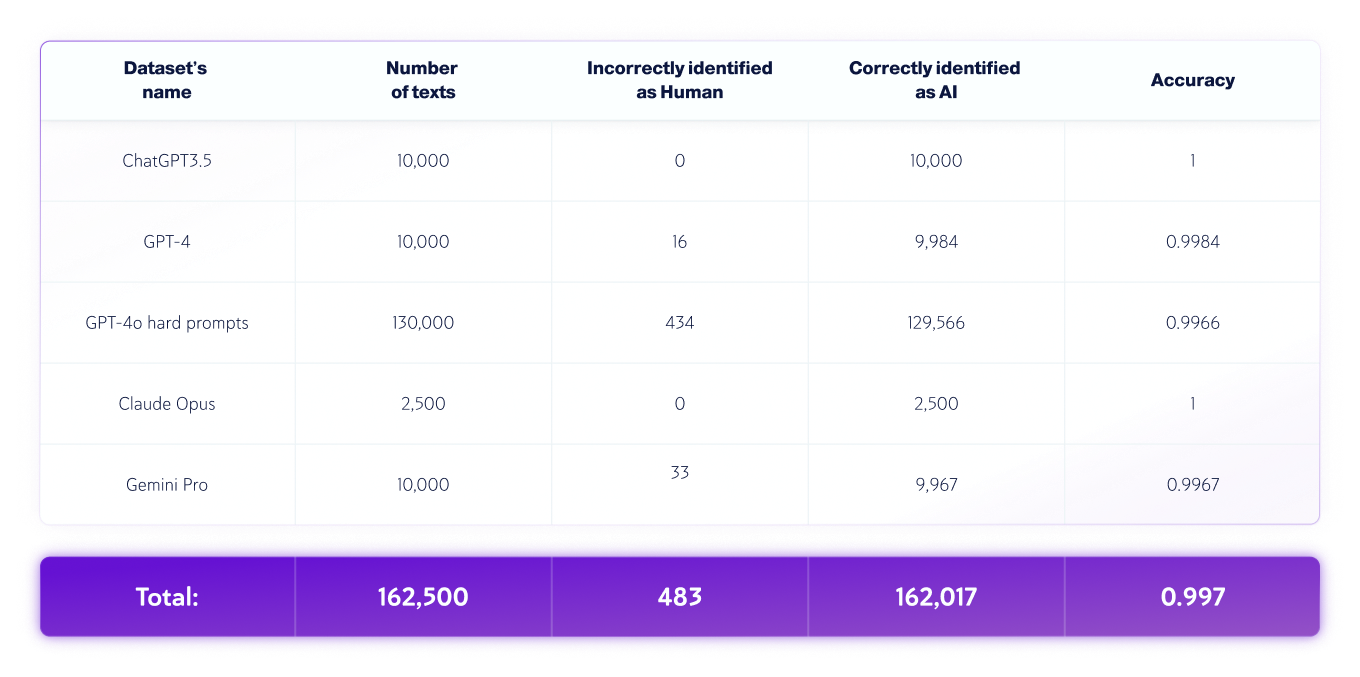
*Model versiyonları zamanla değişebilir. Metinler, yukarıdaki üretken yapay zeka modellerinin mevcut sürümlerinden biri kullanılarak oluşturulmuştur.
İnsan ve Yapay Zeka Metin Hata Analizi
Değerlendirme sürecinde modelin yaptığı hataları tespit edip analiz ediyoruz ve veri bilimi ekibinin bu hataların altında yatan nedenleri düzeltmesini sağlayacak ayrıntılı bir rapor çıkarıyoruz. Bu, hataları veri bilimi ekibine ifşa etmeden yapılır. Tüm hatalar, temel nedenleri anlamayı ve tekrarlanan kalıpları belirlemeyi amaçlayan bir "temel neden analizi süreci" kapsamında, karakter ve doğalarına göre sistematik olarak günlüğe kaydedilir ve kategorize edilir. Bu süreç her zaman devam ediyor ve modelimizin zaman içinde iyileştirilmesini ve uyarlanabilirliğini sağlıyor.
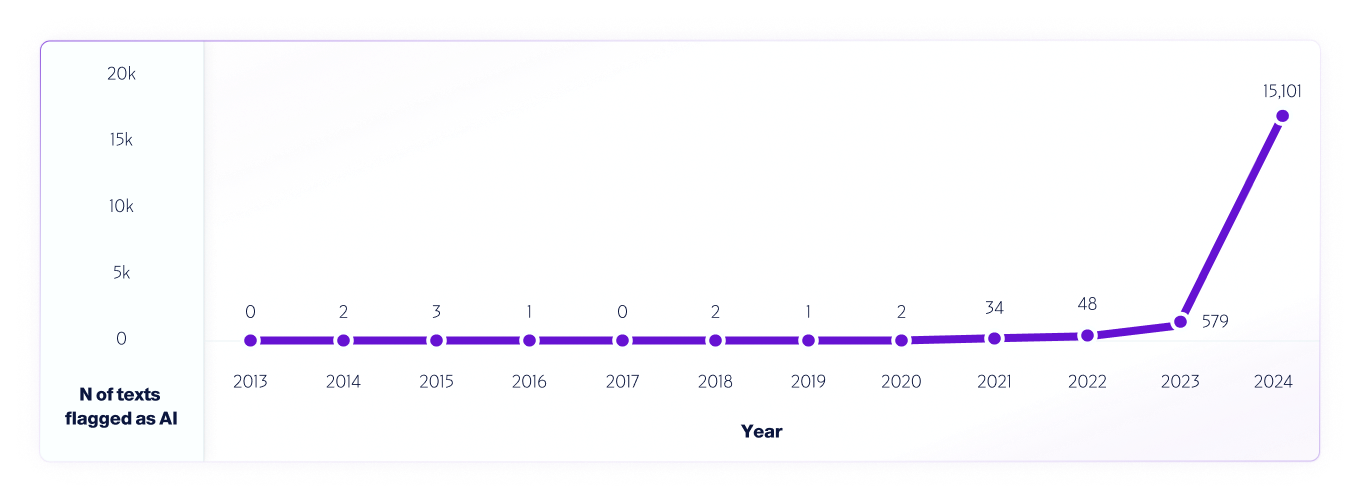
Böyle bir testin bir örneği bizim analizimiz V4 modelimizi kullanarak 2013 – 2024 arasındaki internet verilerinin analizi. KModelin daha da geliştirilmesine yardımcı olmak için, yapay zeka sistemlerinin piyasaya sürülmesinden önce 2013-2020 arasında tespit edilen hatalı pozitifleri kullanarak 2013'ten başlayarak her yıldan 1 milyon metin örneklendi.
Nasıl olduğuna benzer dünya çapındaki araştırmacılar Yeteneklerini ve sınırlamalarını ölçmek için farklı AI dedektör platformlarını test etmiş ve test etmeye devam ediyorsak, kullanıcılarımızı gerçek dünya testleri yapmaya tamamen teşvik ediyoruz. Son olarak, yeni modeller piyasaya sürüldükçe test metodolojilerini, doğruluğunu ve dikkat edilmesi gereken diğer önemli hususları paylaşmaya devam edeceğiz.