الموارد
تقييم دقة Copyleaks كاشف الذكاء الاصطناعي
منهجية خطوة بخطوة
تاريخ الاختبار: 25 مايو 2024
تم اختبار النموذج: V5
نعتقد أنه من المهم أكثر من أي وقت مضى أن نكون شفافين تمامًا بشأن كاشف الذكاء الاصطناعي الدقة، ومعدلات الإيجابيات والسلبيات الكاذبة، ومجالات التحسين، والمزيد لضمان الاستخدام المسؤول والاعتماد. يهدف هذا التحليل الشامل إلى ضمان الشفافية الكاملة حول منهجية اختبار نموذج V5 الخاصة بـ AI Detector.
المنهجية
قام فريق Copyleaks Data Science وQA بإجراء الاختبارات بشكل مستقل لضمان الحصول على نتائج دقيقة وغير متحيزة. اختلفت بيانات الاختبار عن بيانات التدريب ولم تتضمن أي محتوى تم إرساله مسبقًا إلى AI Detector لاكتشاف الذكاء الاصطناعي.
تتألف بيانات الاختبار من نص مكتوب بشريًا مصدره مجموعات بيانات تم التحقق منها ونص تم إنشاؤه بواسطة الذكاء الاصطناعي من نماذج الذكاء الاصطناعي المختلفة. تم إجراء الاختبار باستخدام Copyleaks API.
المقاييس
تتضمن المقاييس الدقة الإجمالية بناءً على معدل تحديد النص الصحيح وغير الصحيح، بالإضافة إلى ROC-AUC (خاصية تشغيل جهاز الاستقبال - المنطقة أسفل المنحنى)، والتي تفحص المعدلات الإيجابية الحقيقية (TPR) والمعدلات الإيجابية الخاطئة (FPR). تشمل المقاييس الإضافية درجة F1 والمعدل السلبي الحقيقي (TNR) والدقة ومصفوفات الارتباك.
نتائج
يتحقق الاختبار من أن AI Detector يعرض دقة اكتشاف عالية للتمييز بين النص المكتوب بواسطة الإنسان والنص الذي تم إنشاؤه بواسطة الذكاء الاصطناعي مع الحفاظ على معدل إيجابي كاذب منخفض.
عملية التقييم
باستخدام نظام ثنائي القسم، قمنا بتصميم عملية التقييم لدينا لضمان أعلى مستوى من الجودة والمعايير والموثوقية. لدينا إدارتان مستقلتان لتقييم النموذج: علم البيانات وفرق ضمان الجودة. يعمل كل قسم بشكل مستقل باستخدام بيانات وأدوات التقييم الخاصة به ولا يمكنه الوصول إلى عملية التقييم الخاصة بالآخر. يضمن هذا الفصل أن تكون نتائج التقييم غير متحيزة وموضوعية ودقيقة مع التقاط جميع الأبعاد المحتملة لأداء نموذجنا. ومن الضروري أيضًا ملاحظة أن بيانات الاختبار منفصلة عن بيانات التدريب، ونحن نختبر نماذجنا فقط على بيانات جديدة لم نرها في الماضي.
المنهجية
قامت فرق ضمان الجودة وعلوم البيانات في Copyleaks بجمع مجموعة متنوعة من مجموعات بيانات الاختبار بشكل مستقل. تتكون كل مجموعة بيانات اختبار من عدد محدود من النصوص. يتم تحديد التسمية المتوقعة - وهي علامة تشير إلى ما إذا كان نص معين قد كتب بواسطة إنسان أو بواسطة الذكاء الاصطناعي - لكل مجموعة بيانات بناءً على مصدر البيانات. تم جمع النصوص البشرية من النصوص المنشورة قبل ظهور أنظمة الذكاء الاصطناعي التوليدية الحديثة أو لاحقًا من خلال مصادر موثوقة أخرى تم التحقق منها مرة أخرى من قبل الفريق. تم إنشاء النصوص التي تم إنشاؤها بواسطة الذكاء الاصطناعي باستخدام مجموعة متنوعة من نماذج وتقنيات الذكاء الاصطناعي.
تم تنفيذ الاختبارات على Copyleaks API. لقد تحققنا مما إذا كانت مخرجات واجهة برمجة التطبيقات (API) صحيحة لكل نص بناءً على التسمية المستهدفة، ثم قمنا بتجميع الدرجات لحساب مصفوفة الارتباك.
النتائج: فريق علوم البيانات
أجرى فريق علوم البيانات الاختبار المستقل التالي:
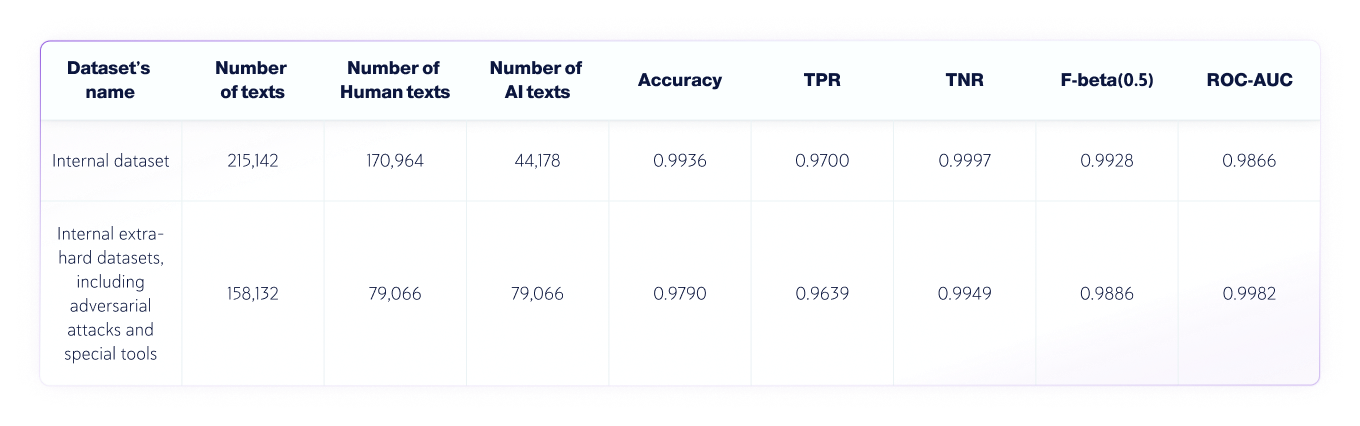
- كانت لغة النصوص هي اللغة الإنجليزية، وتم اختبار 250,030 نصًا مكتوبًا بشريًا و123,244 نصًا تم إنشاؤه بواسطة الذكاء الاصطناعي من مختلف درجات الماجستير في القانون إجمالاً.
- تختلف أطوال النص، لكن مجموعات البيانات تحتوي فقط على نصوص يزيد طولها عن 350 حرفًا - وهو الحد الأدنى الذي يقبله منتجنا.
مقاييس التقييم
المقاييس المستخدمة في مهمة تصنيف النص هذه هي:
1. مصفوفة الارتباك: جدول يوضح TP (الإيجابيات الحقيقية)، FP (الإيجابيات الكاذبة)، TN (السلبيات الحقيقية) وFN (السلبيات الكاذبة).
2. الدقة: نسبة النتائج الحقيقية (الإيجابية والسلبية الحقيقية) بين النتائج إجمالي عدد النصوص التي تم فحصها.

3. TNR: نسبة التنبؤات السلبية الدقيقة في كل التوقعات السلبية.

في سياق اكتشاف الذكاء الاصطناعي، فإن TNR هي دقة النموذج في النصوص البشرية.
4. TPR (المعروف أيضًا باسم الاستدعاء): نسبة النتائج الإيجابية الحقيقية كل التوقعات الفعلية.

في سياق اكتشاف الذكاء الاصطناعي، فإن TPR هي دقة النموذج في النصوص التي ينشئها الذكاء الاصطناعي.
5. نقاط F-beta: المتوسط التوافقي الموزون بين الدقة والتذكير، مع تفضيل الدقة أكثر (حيث أننا نريد تفضيل معدل إيجابي كاذب أقل).

6. ROC-AUC: تقييم التنازل عن ميزة ممن أجل الحصول على أخرى بين TPR وFPR.

الجمع بين الذكاء الاصطناعي ومجموعات البيانات البشرية
النتائج: فريق ضمان الجودة
أجرى فريق ضمان الجودة الاختبار المستقل التالي:
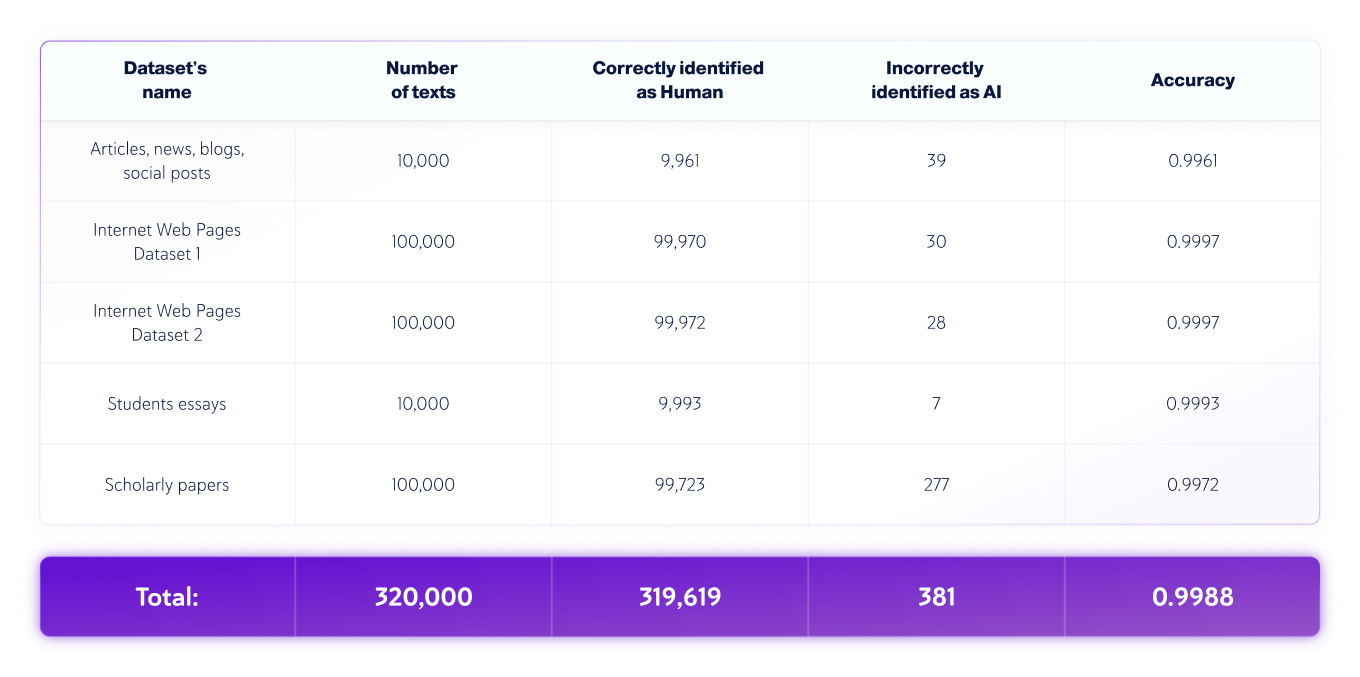
- كانت لغة النص هي اللغة الإنجليزية، وتم اختبار 320.000 نصًا مكتوبًا بشريًا و162.500 نصًا تم إنشاؤه بواسطة الذكاء الاصطناعي من مختلف ماجستير إدارة الأعمال إجمالاً.
- تختلف أطوال النص، لكن مجموعات البيانات تحتوي فقط على نصوص يزيد طولها عن 350 حرفًا - وهو الحد الأدنى الذي يقبله منتجنا.
مجموعات البيانات البشرية فقط
مجموعات بيانات الذكاء الاصطناعي فقط
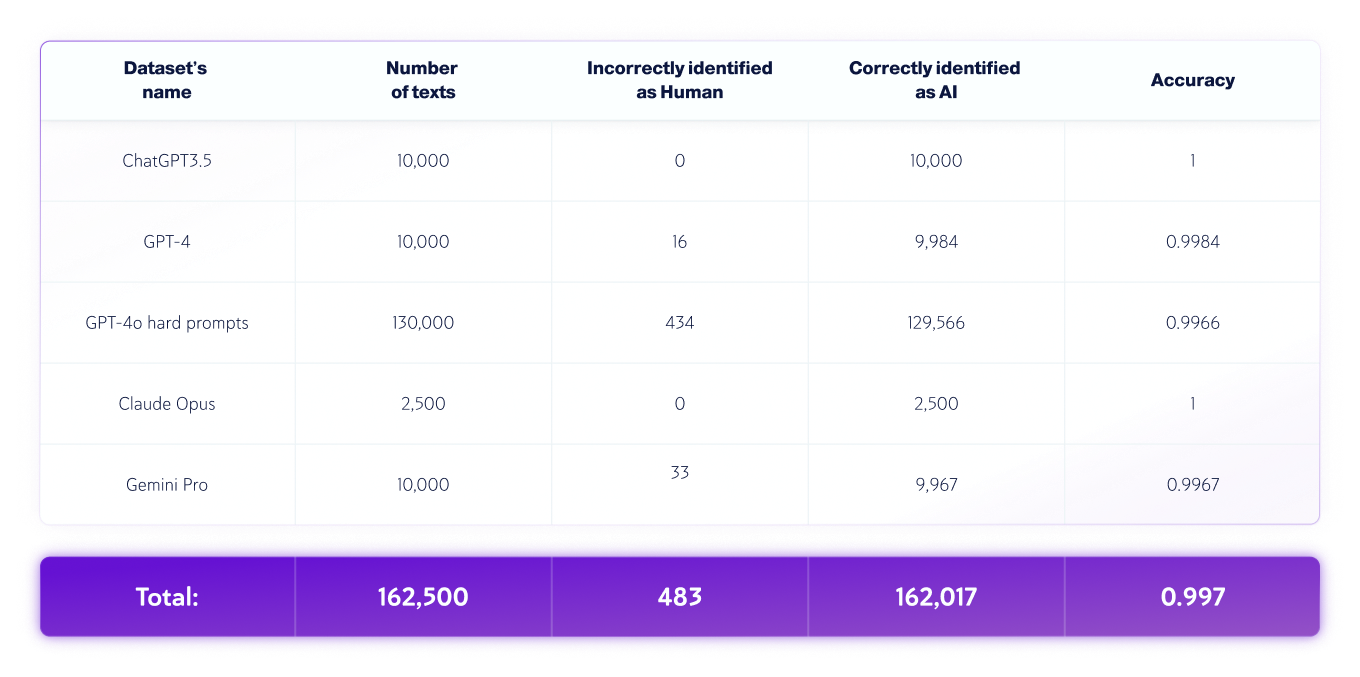
*قد تتغير إصدارات النماذج بمرور الوقت. تم إنشاء النصوص باستخدام أحد الإصدارات المتاحة لنماذج الذكاء الاصطناعي التوليدية المذكورة أعلاه.
تحليل أخطاء النص البشري والذكاء الاصطناعي
أثناء عملية التقييم، نقوم بتحديد وتحليل الأخطاء التي ارتكبها النموذج وإخراج تقرير مفصل سيمكن فريق علم البيانات من تصحيح الأسباب الكامنة وراء هذه الأخطاء. ويتم ذلك دون تعريض الأخطاء نفسها لفريق علم البيانات. يتم تسجيل جميع الأخطاء وتصنيفها بشكل منهجي بناءً على طابعها وطبيعتها في "عملية تحليل السبب الجذري"، والتي تهدف إلى فهم الأسباب الأساسية وتحديد الأنماط المتكررة. هذه العملية مستمرة دائمًا، مما يضمن تحسين نموذجنا وقابليته للتكيف مع مرور الوقت.
أحد الأمثلة على مثل هذا الاختبار هو تحليلنا بيانات الإنترنت من 2013 إلى 2024 باستخدام نموذج V4 الخاص بنا. دبليوقمنا بأخذ عينات من مليون نص من كل عام، بدءًا من عام 2013، باستخدام أي نتائج إيجابية كاذبة تم اكتشافها في الفترة من 2013 إلى 2020، قبل إصدار أنظمة الذكاء الاصطناعي، للمساعدة في تحسين النموذج بشكل أكبر.
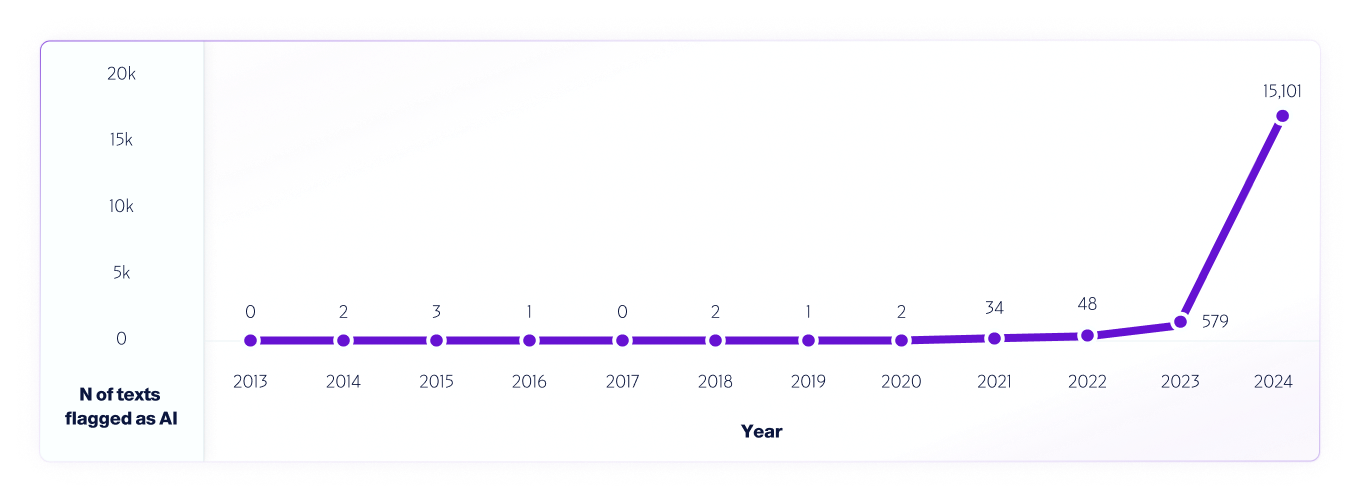
على غرار كيف الباحثين في جميع أنحاء العالم لدينا منصات مختلفة للكشف عن الذكاء الاصطناعي ونستمر في اختبارها لقياس قدراتها وقيودها، ونحن نشجع مستخدمينا تمامًا على إجراء اختبارات في العالم الحقيقي. في النهاية، مع إصدار نماذج جديدة، سنستمر في مشاركة منهجيات الاختبار والدقة والاعتبارات المهمة الأخرى التي يجب أن تكون على دراية بها.