संसाधन
Copyleaks की सटीकता का मूल्यांकन एआई डिटेक्टर
चरण-दर-चरण कार्यप्रणाली
परीक्षा की तारीख: 25 मई, 2024
परीक्षण किया गया मॉडल: वी 5
हमारा मानना है कि एआई डिटेक्टर के बारे में पूरी तरह से पारदर्शी होना पहले से कहीं अधिक महत्वपूर्ण है। सटीकता, गलत सकारात्मक और गलत नकारात्मक की दरें, सुधार के क्षेत्र, और जिम्मेदार उपयोग और अपनाने को सुनिश्चित करने के लिए और भी बहुत कुछ। इस व्यापक विश्लेषण का उद्देश्य हमारे AI डिटेक्टर की V5 मॉडल परीक्षण पद्धति के बारे में पूर्ण पारदर्शिता सुनिश्चित करना है।
क्रियाविधि
Copyleaks डेटा साइंस और QA टीमों ने निष्पक्ष और सटीक परिणाम सुनिश्चित करने के लिए स्वतंत्र रूप से परीक्षण किया। परीक्षण डेटा प्रशिक्षण डेटा से भिन्न था और इसमें AI डिटेक्टर को AI डिटेक्शन के लिए पहले से सबमिट की गई कोई सामग्री शामिल नहीं थी।
परीक्षण डेटा में सत्यापित डेटासेट से प्राप्त मानव-लिखित पाठ और विभिन्न AI मॉडल से AI-जनरेटेड पाठ शामिल थे। परीक्षण Copyleaks API के साथ किया गया था।
मेट्रिक्स
मेट्रिक्स में ROC-AUC (रिसीवर ऑपरेटिंग कैरेक्टरिस्टिक - एरिया अंडर द कर्व) के अलावा सही और गलत टेक्स्ट पहचान की दर के आधार पर समग्र सटीकता शामिल है, जो सच्ची सकारात्मक दरों (TPR) और झूठी सकारात्मक दरों (FPR) की जांच करती है। अतिरिक्त मेट्रिक्स में F1 स्कोर, सच्ची नकारात्मक दर (TNR), सटीकता और भ्रम मैट्रिक्स शामिल हैं।
परिणाम
परीक्षण से यह पुष्टि होती है कि AI डिटेक्टर मानव-लिखित और AI-जनित पाठ के बीच अंतर करने के लिए उच्च पहचान सटीकता प्रदर्शित करता है, जबकि झूठी सकारात्मक दर कम बनाए रखता है।
मूल्यांकन प्रक्रिया
दोहरे विभाग प्रणाली का उपयोग करते हुए, हमने शीर्ष-स्तरीय गुणवत्ता, मानकों और विश्वसनीयता सुनिश्चित करने के लिए अपनी मूल्यांकन प्रक्रिया को डिज़ाइन किया है। हमारे पास मॉडल का मूल्यांकन करने वाले दो स्वतंत्र विभाग हैं: डेटा विज्ञान और QA टीम। प्रत्येक विभाग अपने मूल्यांकन डेटा और उपकरणों के साथ स्वतंत्र रूप से काम करता है और दूसरे की मूल्यांकन प्रक्रिया तक उसकी पहुँच नहीं होती है। यह पृथक्करण सुनिश्चित करता है कि मूल्यांकन के परिणाम निष्पक्ष, वस्तुनिष्ठ और सटीक हों, जबकि हमारे मॉडल के प्रदर्शन के सभी संभावित आयामों को कैप्चर किया जाता है। साथ ही, यह ध्यान रखना आवश्यक है कि परीक्षण डेटा को प्रशिक्षण डेटा से अलग किया जाता है, और हम अपने मॉडल का परीक्षण केवल नए डेटा पर करते हैं जिसे उन्होंने अतीत में नहीं देखा है।
क्रियाविधि
Copyleaks की QA और डेटा साइंस टीमों ने स्वतंत्र रूप से कई तरह के परीक्षण डेटासेट एकत्र किए हैं। प्रत्येक परीक्षण डेटासेट में सीमित संख्या में टेक्स्ट होते हैं। अपेक्षित लेबल - एक मार्कर जो यह दर्शाता है कि कोई विशिष्ट टेक्स्ट किसी मानव द्वारा लिखा गया था या AI द्वारा - प्रत्येक डेटासेट का डेटा के स्रोत के आधार पर निर्धारित किया जाता है। मानव टेक्स्ट आधुनिक जनरेटिव AI सिस्टम के उदय से पहले या बाद में अन्य विश्वसनीय स्रोतों द्वारा प्रकाशित टेक्स्ट से एकत्र किए गए थे जिन्हें टीम द्वारा फिर से सत्यापित किया गया था। AI द्वारा जनरेटेड टेक्स्ट कई तरह के जनरेटिव AI मॉडल और तकनीकों का उपयोग करके तैयार किए गए थे।
परीक्षण Copyleaks API के विरुद्ध निष्पादित किए गए थे। हमने जाँच की कि क्या API का आउटपुट लक्ष्य लेबल के आधार पर प्रत्येक पाठ के लिए सही था, और फिर भ्रम मैट्रिक्स की गणना करने के लिए स्कोर को एकत्रित किया।
परिणाम: डेटा साइंस टीम
डेटा साइंस टीम ने निम्नलिखित स्वतंत्र परीक्षण किया:
- पाठ्यों की भाषा अंग्रेजी थी, और कुल मिलाकर 250,030 मानव-लिखित पाठ्यों और विभिन्न एलएलएम से 123,244 एआई-जनित पाठ्यों का परीक्षण किया गया.
- पाठ की लंबाई अलग-अलग होती है, लेकिन डेटासेट में केवल 350 अक्षरों से अधिक लंबाई वाले पाठ होते हैं - जो कि हमारा उत्पाद न्यूनतम स्वीकार करता है।
मूल्यांकन मेट्रिक्स
इस पाठ वर्गीकरण कार्य में प्रयुक्त मेट्रिक्स हैं:
1. भ्रम मैट्रिक्स: एक तालिका जो टीपी (सच्चे सकारात्मक), एफपी (झूठे सकारात्मक), टीएन (सच्चे नकारात्मक) और एफएन (झूठे नकारात्मक) को दर्शाती है।
2. सटीकता: सही परिणामों (सच्चे सकारात्मक और सच्चे नकारात्मक दोनों) का अनुपात कुल पाठों की संख्या जिनकी जांच की गई।

3. टीएनआर: सटीक नकारात्मक भविष्यवाणियों का अनुपात सभी नकारात्मक भविष्यवाणियाँ.

एआई पहचान के संदर्भ में, टीएनआर मानव पाठ पर मॉडल की सटीकता है।
4. टीपीआर (जिसे रिकॉल भी कहा जाता है): सच्चे सकारात्मक परिणामों का अनुपात सभी वास्तविक भविष्यवाणियाँ.

एआई पहचान के संदर्भ में, टीपीआर एआई-जनरेटेड टेक्स्ट पर मॉडल की सटीकता है।
5. एफ-बीटा स्कोर: परिशुद्धता और स्मरण के बीच भारित हार्मोनिक माध्य, परिशुद्धता को अधिक महत्व देता है (क्योंकि हम कम मिथ्या सकारात्मक दर का पक्ष लेना चाहते हैं).

6. आरओसी-एयूसी: का मूल्यांकन अदला - बदली टीपीआर और एफपीआर के बीच.

संयुक्त एआई और मानव डेटासेट
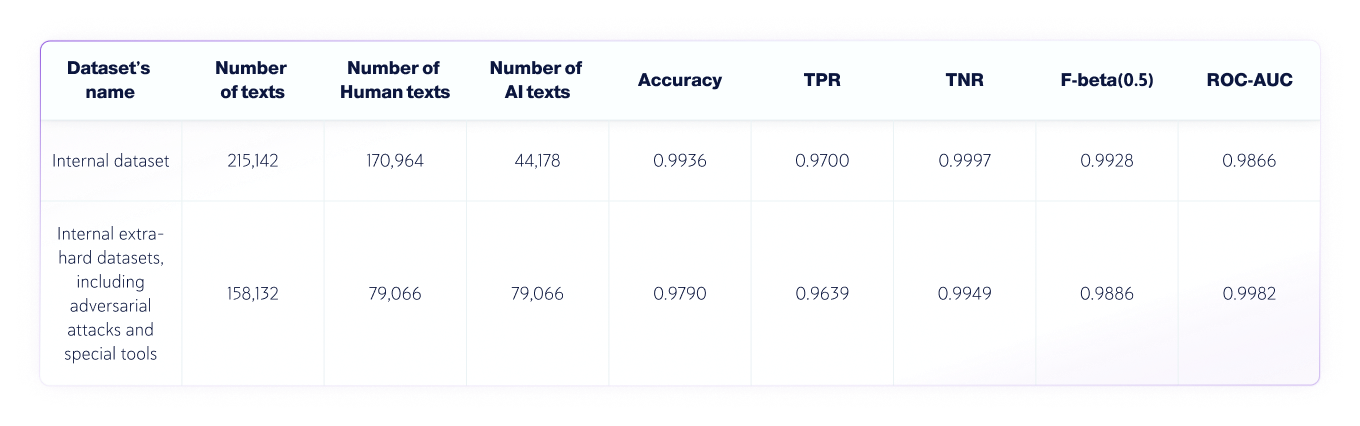
परिणाम: क्यूए टीम
क्यूए टीम ने निम्नलिखित स्वतंत्र परीक्षण किया:
- पाठ की भाषा अंग्रेजी थी, और कुल मिलाकर 320,000 मानव-लिखित पाठ और विभिन्न एलएलएम से 162,500 एआई-जनरेटेड पाठ का परीक्षण किया गया था.
- पाठ की लंबाई अलग-अलग होती है, लेकिन डेटासेट में केवल 350 अक्षरों से अधिक लंबाई वाले पाठ होते हैं - जो कि हमारा उत्पाद न्यूनतम स्वीकार करता है।
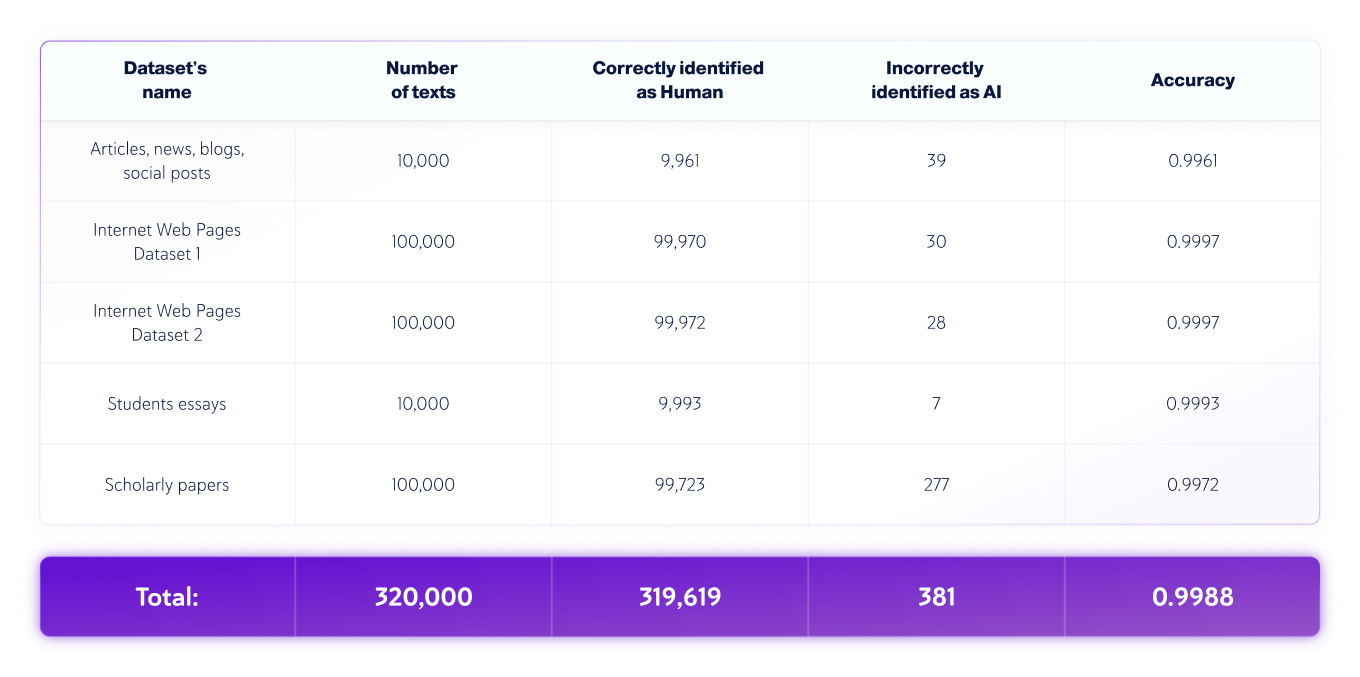
केवल मानव डेटासेट
केवल AI डेटासेट
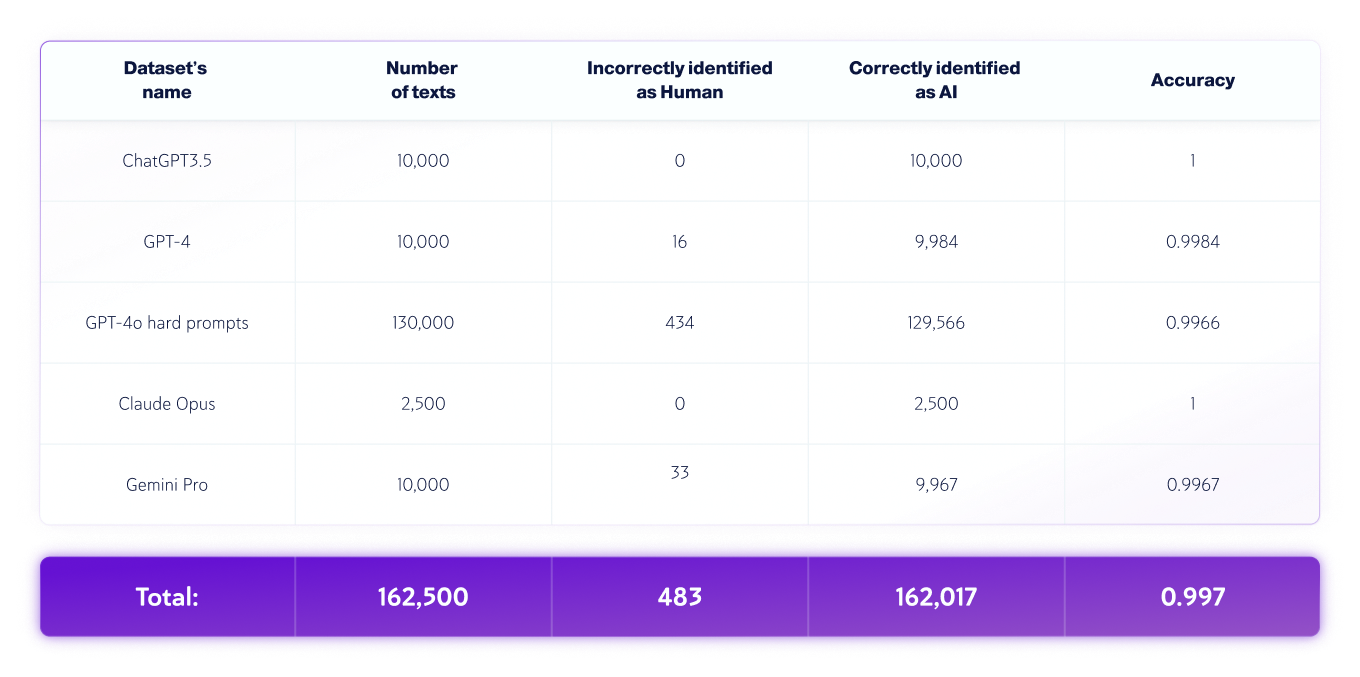
*मॉडल के संस्करण समय के साथ बदल सकते हैं। उपरोक्त जनरेटिव AI मॉडल के उपलब्ध संस्करणों में से एक का उपयोग करके पाठ तैयार किए गए थे।
मानव और AI पाठ त्रुटि विश्लेषण
मूल्यांकन प्रक्रिया के दौरान, हम मॉडल द्वारा की गई गलतियों की पहचान करते हैं और उनका विश्लेषण करते हैं तथा एक विस्तृत रिपोर्ट तैयार करते हैं, जो डेटा विज्ञान टीम को इन गलतियों के अंतर्निहित कारणों को ठीक करने में सक्षम बनाएगी। यह डेटा विज्ञान टीम के सामने त्रुटियों को उजागर किए बिना किया जाता है। सभी त्रुटियों को व्यवस्थित रूप से लॉग किया जाता है और "मूल कारण विश्लेषण प्रक्रिया" में उनके चरित्र और प्रकृति के आधार पर वर्गीकृत किया जाता है, जिसका उद्देश्य अंतर्निहित कारणों को समझना और दोहराए गए पैटर्न की पहचान करना है। यह प्रक्रिया हमेशा चलती रहती है, जिससे समय के साथ हमारे मॉडल में सुधार और अनुकूलनशीलता सुनिश्चित होती है।
ऐसे परीक्षण का एक उदाहरण है हमारा विश्लेषण हमारे V4 मॉडल का उपयोग करके 2013 से 2024 तक इंटरनेट डेटा का।हमने मॉडल को और बेहतर बनाने में मदद करने के लिए, एआई सिस्टम जारी होने से पहले, 2013-2020 से पता लगाए गए किसी भी गलत सकारात्मक का उपयोग करते हुए, 2013 से शुरू करके प्रत्येक वर्ष से 1 मिलियन टेक्स्ट का नमूना लिया।
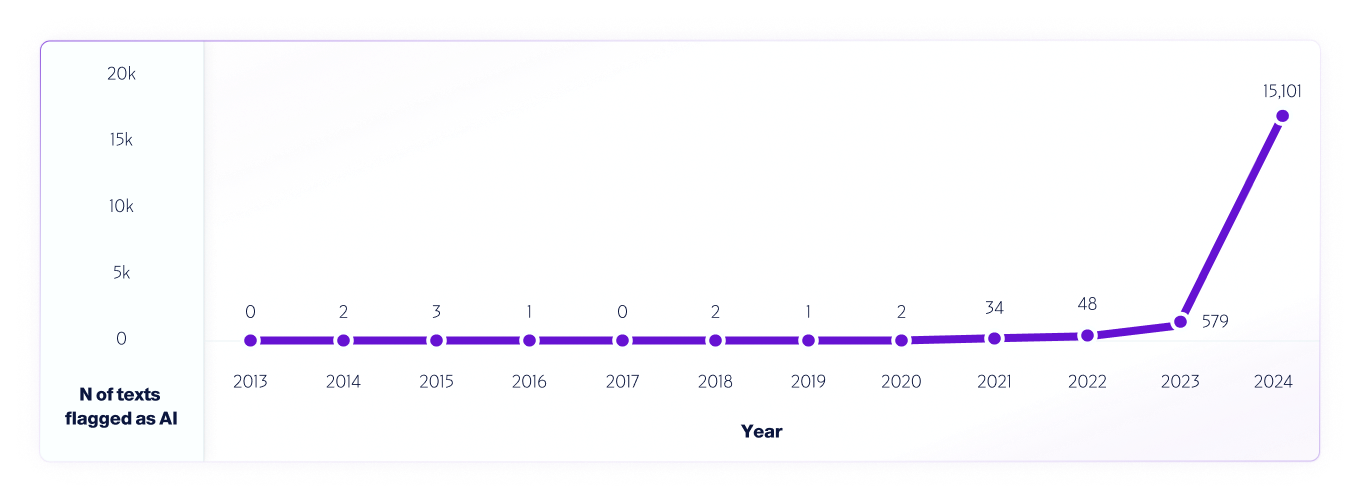
इसी प्रकार दुनिया भर के शोधकर्ता विभिन्न AI डिटेक्टर प्लेटफ़ॉर्म की क्षमताओं और सीमाओं का आकलन करने के लिए उनका परीक्षण करना जारी रखें, हम अपने उपयोगकर्ताओं को वास्तविक दुनिया में परीक्षण करने के लिए पूरी तरह से प्रोत्साहित करते हैं। अंततः, जैसे-जैसे नए मॉडल जारी किए जाएँगे, हम परीक्षण पद्धतियों, सटीकता और अन्य महत्वपूर्ण बातों को साझा करना जारी रखेंगे, जिनके बारे में जागरूक होना चाहिए।