Ресурс
Оценка точности Copyleaks ИИ-детектор
Пошаговая методология
Дата испытаний: 25 мая 2024 г.
Модель протестирована: V5
Мы считаем, что как никогда важно быть полностью прозрачными в отношении работы AI Detector. точность, уровень ложноположительных и ложноотрицательных результатов, области для улучшения и многое другое для обеспечения ответственного использования и внедрения. Этот комплексный анализ направлен на обеспечение полной прозрачности методологии тестирования модели V5 нашего AI Detector.
Методология
Команды анализа данных и контроля качества Copyleaks независимо провели тестирование, чтобы обеспечить объективные и точные результаты. Данные тестирования отличались от данных обучения и не содержали контента, ранее отправленного в AI Detector для обнаружения AI.
Данные тестирования состояли из написанного человеком текста, полученного из проверенных наборов данных, и текста, сгенерированного ИИ из различных моделей ИИ. Тест проводился с использованием API Copyleaks.
Метрики
Метрики включают общую точность, основанную на частоте правильной и неправильной идентификации текста, а также ROC-AUC (рабочая характеристика приемника — площадь под кривой), которая оценивает долю истинно положительных результатов (TPR) и долю ложных срабатываний (FPR). Дополнительные показатели включают оценку F1, истинно отрицательный показатель (TNR), точность и матрицы путаницы.
Полученные результаты
Тестирование подтверждает, что AI Detector демонстрирует высокую точность обнаружения, позволяя различать текст, написанный человеком, и текст, сгенерированный искусственным интеллектом, сохраняя при этом низкий уровень ложных срабатываний.
Процесс оценки
Используя систему двух отделов, мы разработали процесс оценки таким образом, чтобы обеспечить высочайший уровень качества, стандартов и надежности. У нас есть два независимых отдела, оценивающих модель: отдел обработки данных и отдел контроля качества. Каждый отдел работает независимо со своими данными и инструментами оценки и не имеет доступа к процессу оценки другого. Такое разделение гарантирует, что результаты оценки будут беспристрастными, объективными и точными, охватывая при этом все возможные аспекты эффективности нашей модели. Кроме того, важно отметить, что данные тестирования отделены от данных обучения, и мы тестируем наши модели только на новых данных, которых они не видели раньше.
Методология
Команды контроля качества и анализа данных Copyleaks независимо собрали различные наборы тестовых данных. Каждый набор тестовых данных состоит из конечного числа текстов. Ожидаемая метка — маркер, указывающий, был ли конкретный текст написан человеком или искусственным интеллектом — каждого набора данных определяется на основе источника данных. Человеческие тексты были собраны из текстов, опубликованных до появления современных генеративных систем искусственного интеллекта или позже из других надежных источников, которые были снова проверены командой. Тексты, сгенерированные ИИ, были созданы с использованием различных генеративных моделей и методов ИИ.
Тесты проводились с использованием API Copyleaks. Мы проверили, верны ли выходные данные API для каждого текста на основе целевой метки, а затем агрегировали оценки для расчета матрицы путаницы.
Результаты: Команда по науке о данных
Команда Data Science провела следующий независимый тест:
- Языком текстов был английский, всего было протестировано 250 030 текстов, написанных человеком, и 123 244 текста, сгенерированных искусственным интеллектом из различных LLM..
- Длина текста различается, но наборы данных содержат только тексты длиной более 350 символов — минимум, который принимает наш продукт.
Метрики оценки
Метрики, которые используются в этой задаче классификации текста:
1. Матрица путаницы: таблица, в которой показаны TP (истинно положительные результаты), FP (ложно положительные результаты), TN (истинно отрицательные результаты) и FN (ложно отрицательные результаты).
2. Точность: доля истинных результатов (как истинно положительных, так и истинно отрицательных) среди общее количество текстов которые были проверены.

3. TNR: доля точных отрицательных прогнозов в все негативные прогнозы.

В контексте обнаружения ИИ TNR — это точность модели в отношении человеческих текстов.
4. TPR (также известный как отзыв): доля истинно положительных результатов в все реальные прогнозы.

В контексте обнаружения ИИ TPR — это точность модели в отношении текстов, сгенерированных ИИ.
5. Оценка F-бета: среднее взвешенное гармоническое между точностью и отзывом, больше отдавая предпочтение точности (поскольку мы хотим отдать предпочтение более низкому уровню ложноположительных результатов).

6. РПЦ-АУК: Оценка компромисс между ТПР и ФПР.

Комбинированные наборы данных искусственного интеллекта и человека
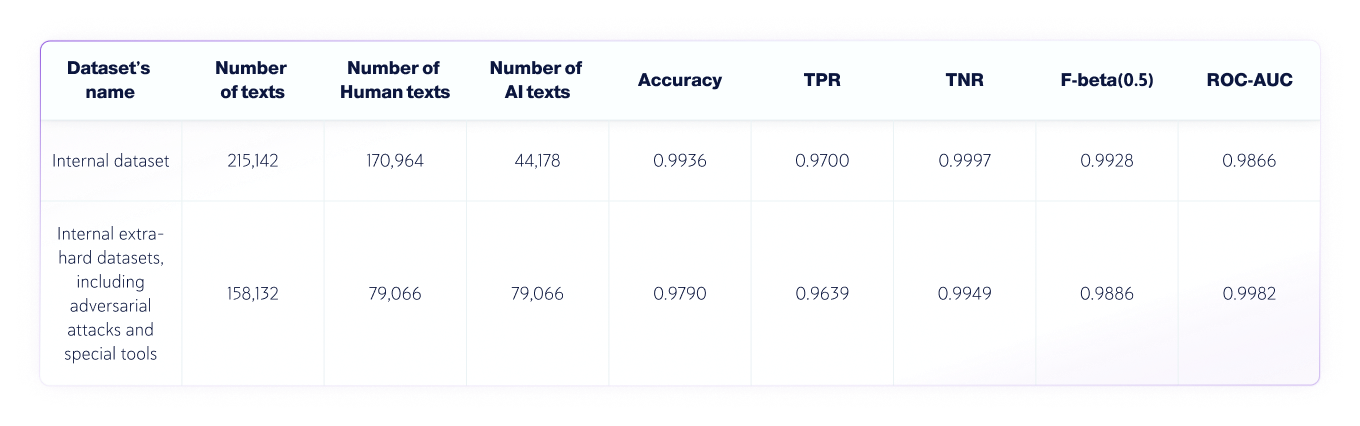
Результаты: команда контроля качества
Команда контроля качества провела следующий независимый тест:
- Язык текста был английский, всего было протестировано 320 000 текстов, написанных человеком, и 162 500 текстов, созданных искусственным интеллектом из различных LLM..
- Длина текста различается, но наборы данных содержат только тексты длиной более 350 символов — минимум, который принимает наш продукт.
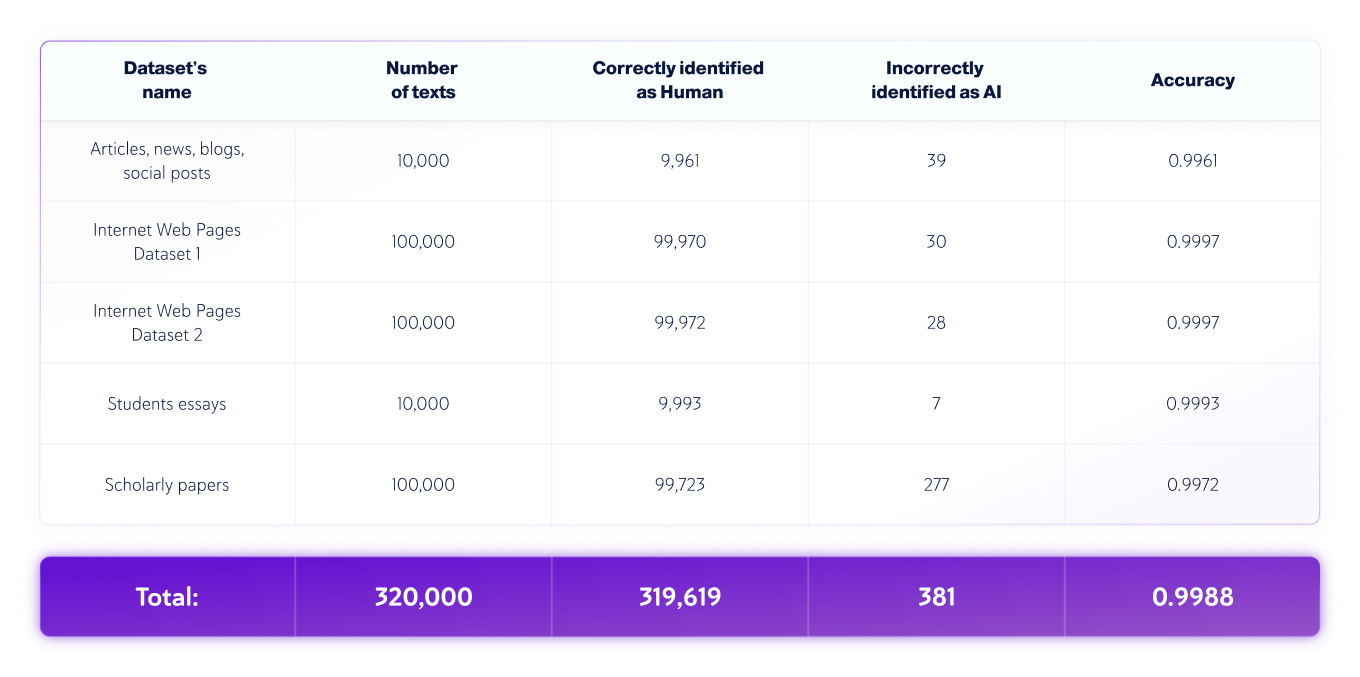
Наборы данных, предназначенные только для людей
Наборы данных только для ИИ
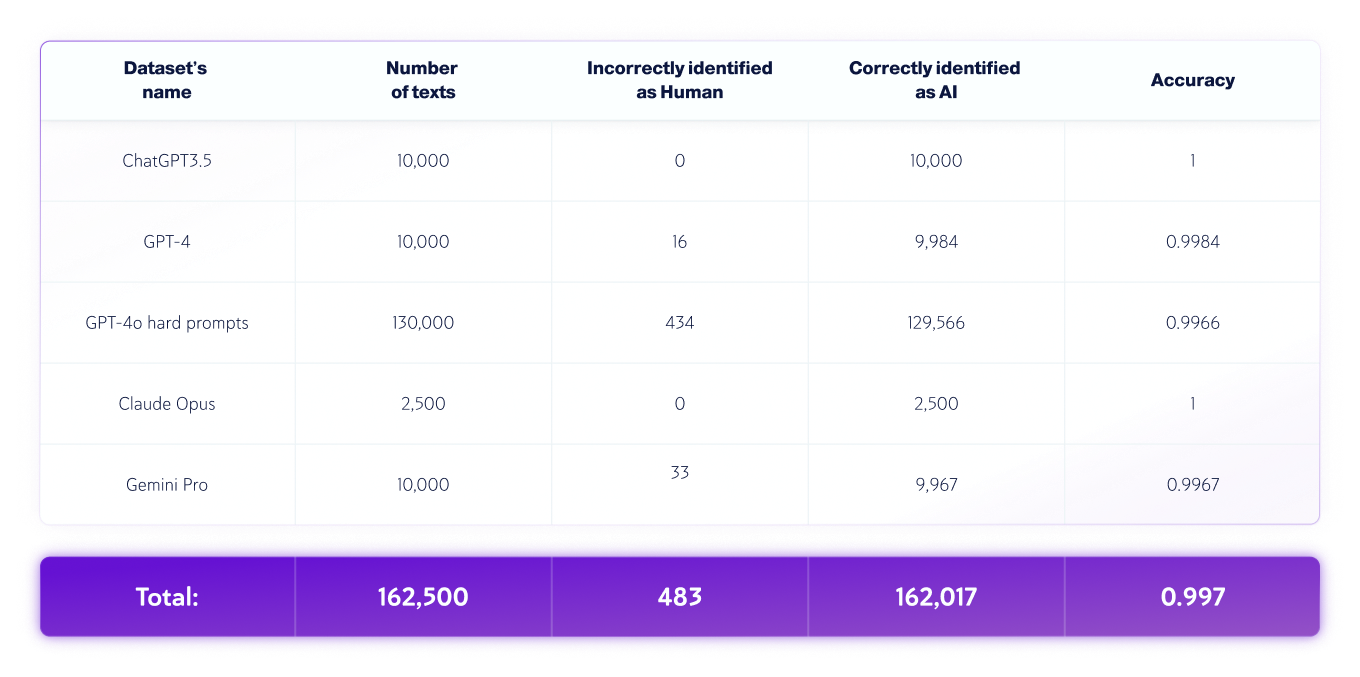
*Версии моделей могут меняться со временем. Тексты были сгенерированы с использованием одной из доступных версий вышеперечисленных генеративных моделей ИИ.
Анализ текстовых ошибок человека и искусственного интеллекта
В процессе оценки мы выявляем и анализируем ошибки, допущенные моделью, и выдаем подробный отчет, который позволит команде по обработке данных исправить основные причины этих ошибок. Это делается без раскрытия самих ошибок команде по анализу данных. Все ошибки систематически регистрируются и классифицируются в зависимости от их характера и характера в рамках «процесса анализа первопричин», целью которого является понимание основных причин и выявление повторяющихся закономерностей. Этот процесс постоянно продолжается, обеспечивая с течением времени улучшение и адаптируемость нашей модели.
Одним из примеров такого теста является наш анализ интернет-данных за 2013–2024 годы с использованием нашей модели V4. ВтМы отобрали 1 млн текстов каждый год, начиная с 2013 года, используя все ложные срабатывания, обнаруженные в 2013–2020 годах, до выпуска систем искусственного интеллекта, чтобы помочь в дальнейшем усовершенствовании модели.
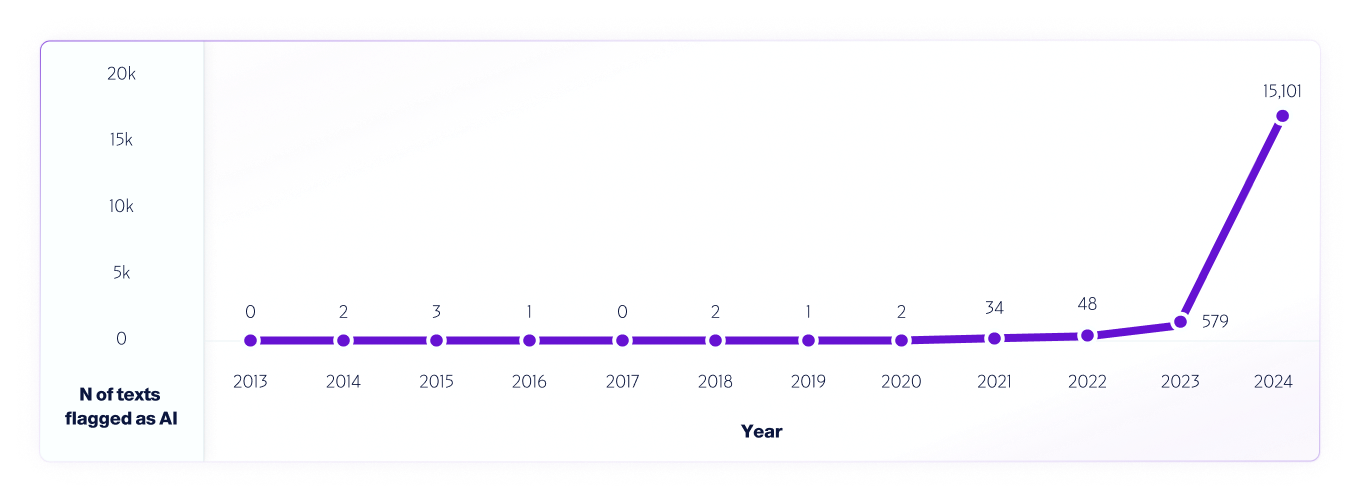
Подобно тому, как исследователи по всему миру Имея и продолжая тестировать различные платформы детекторов искусственного интеллекта, чтобы оценить их возможности и ограничения, мы полностью призываем наших пользователей проводить испытания в реальных условиях. В конечном итоге, по мере выпуска новых моделей мы продолжим делиться методологиями тестирования, точностью и другими важными моментами, о которых следует знать.