リソース
テスト日: 2025年1月15日
公開日: 2025年2月18日
テスト済みモデル: V8
AI検出器の透明性がこれまで以上に重要だと考えています。 責任ある使用と採用を確実にするために、精度、誤検知と誤検知の率、改善の余地などについて分析します。この包括的な分析は、AI Detector の V8 モデル テスト方法論に関する完全な透明性を確保することを目的としています。
Copyleaks データ サイエンス チームと QA チームは、偏りのない正確な結果を保証するために独立してテストを実施しました。テスト データはトレーニング データとは異なり、AI 検出のために AI 検出器に以前に送信されたコンテンツは含まれていませんでした。
テストデータは、検証済みのデータセットから取得した人間が書いたテキストと、さまざまな AI モデルから AI が生成したテキストで構成されていました。テストは Copyleaks API を使用して実行されました。
メトリックには、正しいテキスト識別と誤ったテキスト識別の率に基づく全体的な精度、F1 スコア、真陰性率 (TNR)、真陽性率 (TPR)、精度、混同マトリックスが含まれます。
テストでは、AI 検出器が、低い誤検出率を維持しながら、人間が書いたテキストと AI が生成したテキストを区別する高い検出精度を示すことが確認されています。
2 部門システムを使用して、最高レベルの品質、標準、信頼性を確保するための評価プロセスを設計しました。モデルを評価する部門は 2 つあり、データ サイエンス チームと QA チームです。各部門は評価データとツールを独立して使用し、他の部門の評価プロセスにはアクセスできません。この分離により、評価結果が偏りがなく、客観的で正確になり、モデルのパフォーマンスのあらゆる側面が把握されます。また、テスト データはトレーニング データから分離されており、モデルは過去に見たことのない新しいデータでのみテストされることに注意してください。
Copyleaks の QA チームとデータ サイエンス チームは、さまざまなテスト データセットを個別に収集しました。各テスト データセットは、有限数のテキストで構成されています。各データセットの想定ラベル (特定のテキストが人間によって書かれたものか AI によって書かれたものかを示すマーカー) は、データのソースに基づいて決定されます。人間のテキストは、現代の生成 AI システムが出現する前に公開されたテキスト、または後にチームによって再度検証された他の信頼できるソースから収集されました。AI によって生成されたテキストは、さまざまな生成 AI モデルとテクニックを使用して生成されました。
テストは Copyleaks API に対して実行されました。ターゲット ラベルに基づいて各テキストに対して API の出力が正しいかどうかを確認し、スコアを集計して混同行列を計算しました。
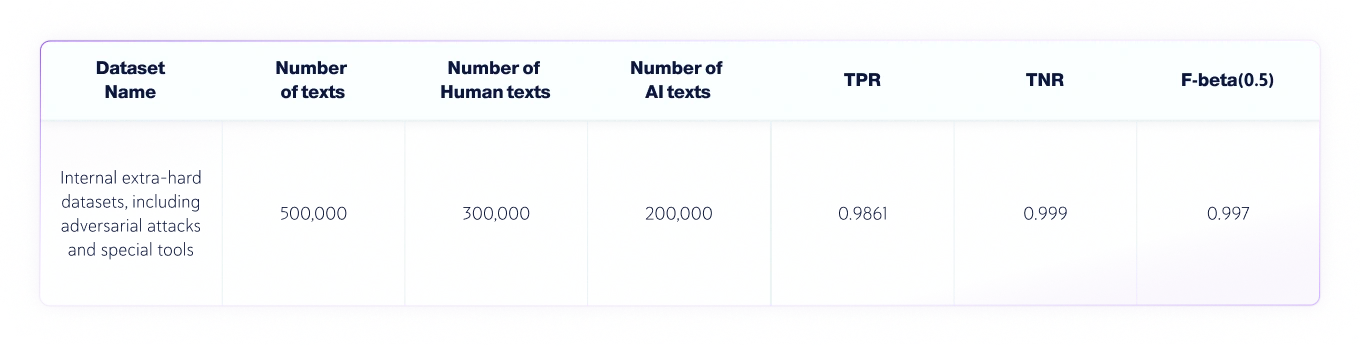
データ サイエンス チームは、次の独立したテストを実施しました。
このテキスト分類タスクで使用されるメトリックは次のとおりです。
1. 混同マトリックス: TP (真陽性)、FP (偽陽性)、TN (真陰性)、FN (偽陰性) を示す表。
2. 正確性: 真の結果(真陽性と真陰性の両方)の割合 テキストの総数 チェックされたもの。
3. TNR: 正確な否定的予測の割合 すべての否定的な予測.
AI 検出の文脈では、TNR は人間のテキストに対するモデルの精度です。
4. TPR(リコールとも呼ばれる): 実際の予測はすべて.
AI 検出のコンテキストでは、TPR は AI によって生成されたテキストに対するモデルの精度です。
5. Fベータスコア: 適合率と再現率の間の加重調和平均。適合率を優先します(偽陽性率を低くしたいため)。.
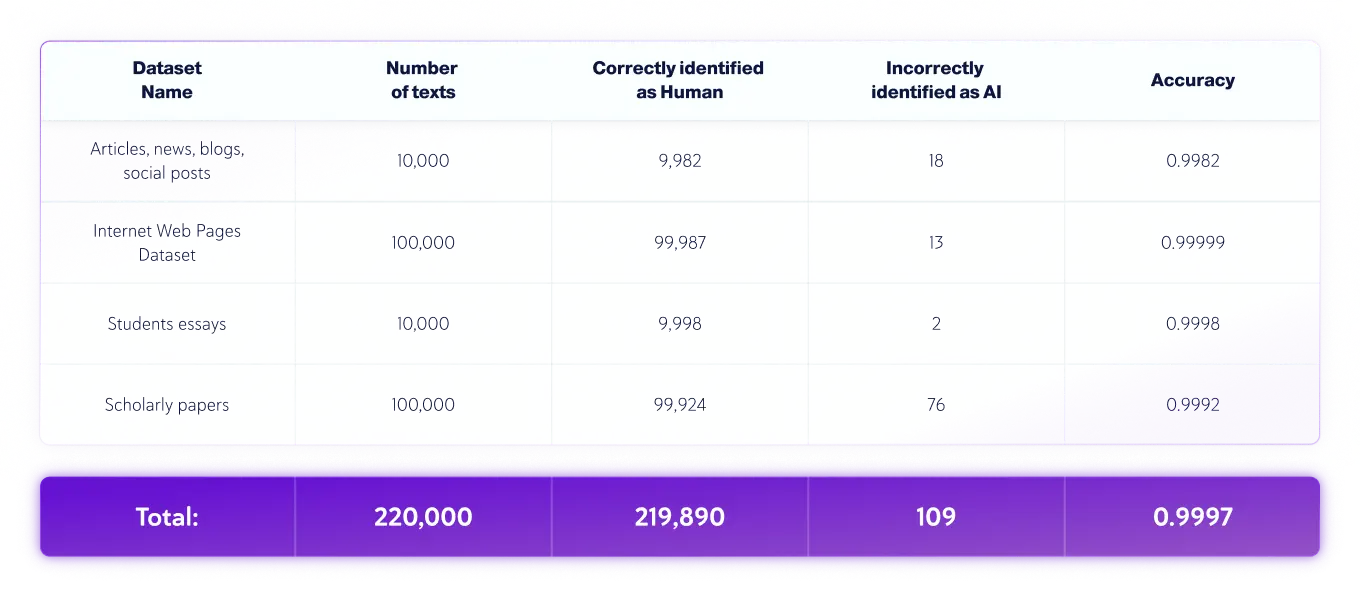
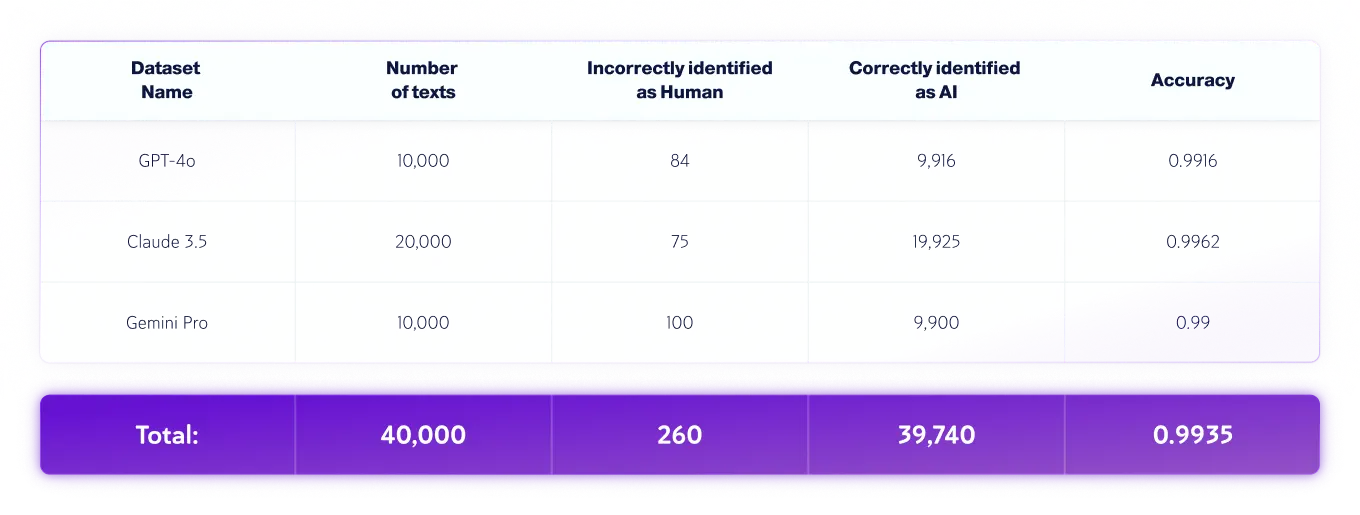
QA チームは次の独立したテストを実施しました。
*モデルのバージョンは時間の経過とともに変更される可能性があります。テキストは、上記の生成 AI モデルの利用可能なバージョンのいずれかを使用して生成されました。
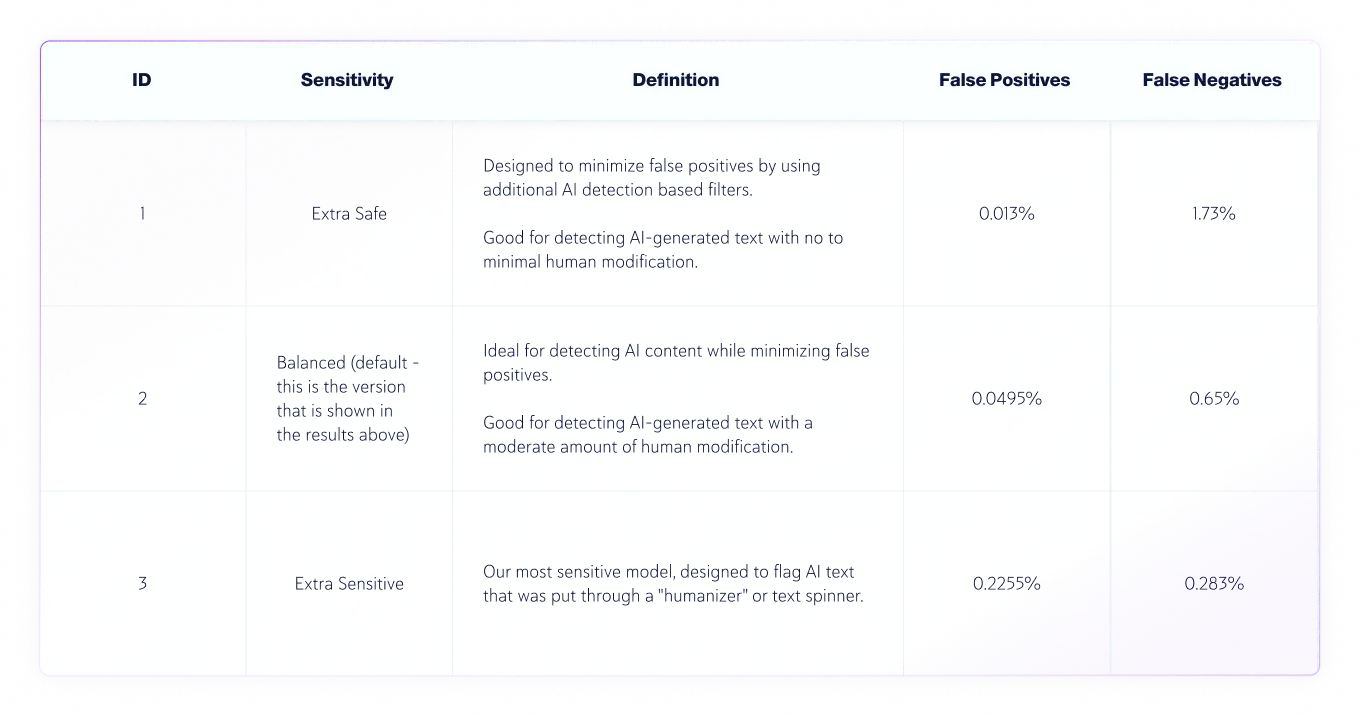
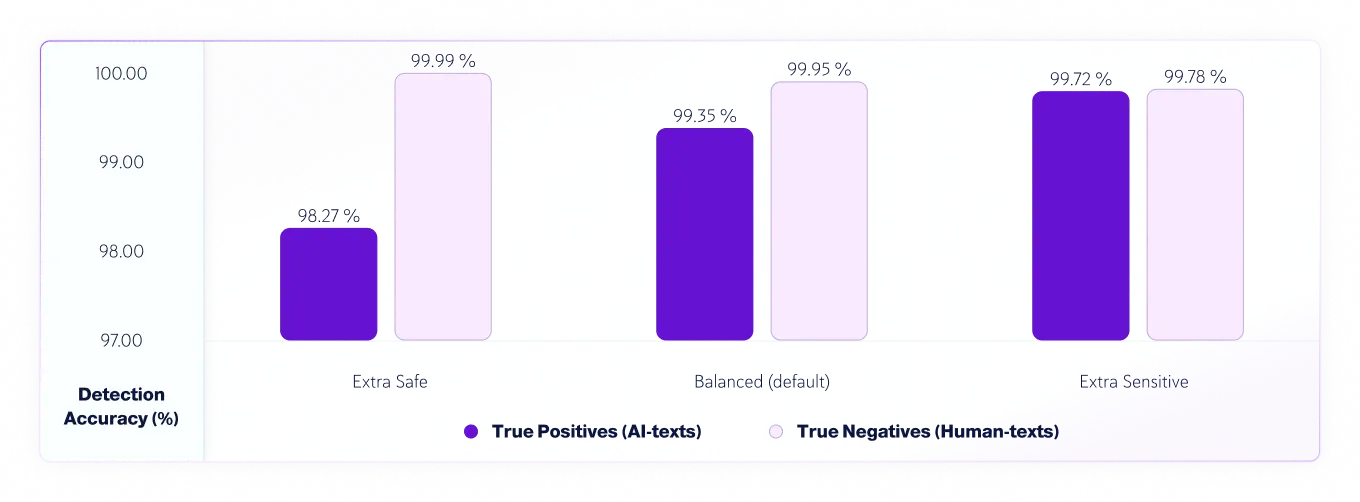
v7.1 以降、AI 検出モデルには 3 つの感度レベルがあります。以下は、モデル v8 の感度レベルのテスト結果です。
真陽性(AIテキスト)と真陰性(人間のテキスト)の感度による精度
評価プロセスでは、モデルによる誤った評価を特定して分析し、データ サイエンス チームが根本的な原因を修正できるように詳細なレポートを作成しました。これは、データ サイエンス チームに誤った評価を公開することなく行われます。すべてのエラーは、根本的な原因を理解し、繰り返されるパターンを特定することを目的とした「根本原因分析プロセス」で、その特徴と性質に基づいて体系的に記録および分類されます。このプロセスは常に継続しており、時間の経過とともにモデルの継続的な改善と適応性を確保します。
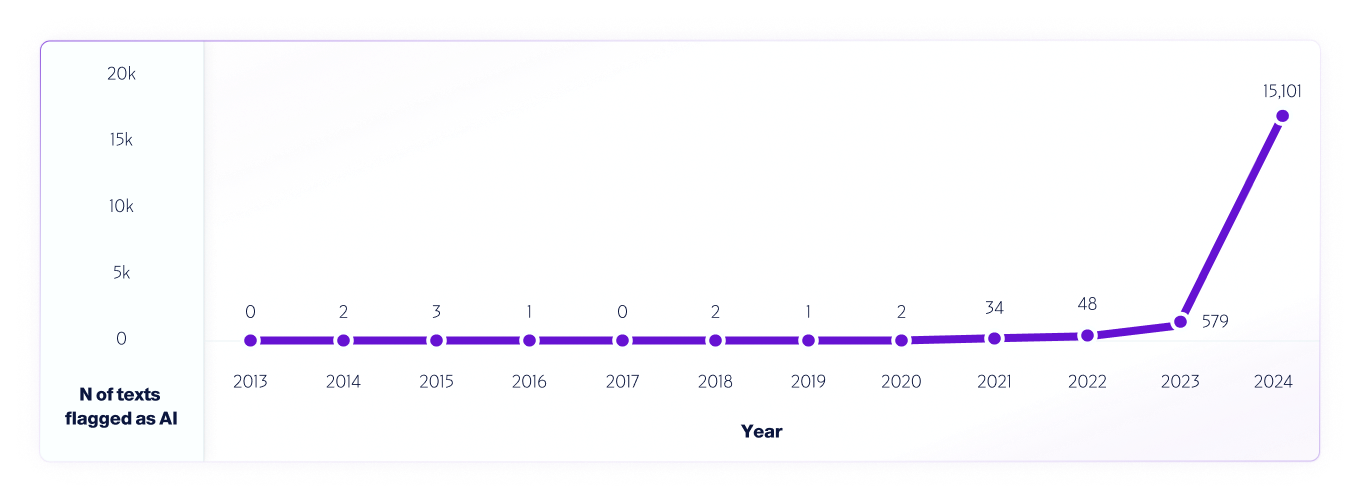
そのようなテストの一例としては 私たちの分析 2013年から2024年までのインターネット データを V4 モデルを使用して分析しました。AI システムのリリース前の 2013 年から 2020 年に検出された誤検知を使用して、2013 年から毎年 100 万件のテキストをサンプリングし、モデルのさらなる改善に役立てました。
同様に 世界中の研究者 当社は、さまざまな AI 検出器プラットフォームをテストしてその機能と限界を測定しており、今後もテストを継続する予定です。ユーザーの皆様には、実際の環境でテストを実施していただくことを強く推奨します。最終的には、新しいモデルがリリースされるたびに、テスト方法、精度、その他の重要な考慮事項を引き続き共有していきます。