Recurso
Evaluación de la precisión del Copyleaks Detector de IA
Una metodología paso a paso
Creemos que es más importante que nunca ser completamente transparentes sobre el Detector de IA. Precisión, tasas de falsos positivos y falsos negativos, áreas de mejora y más para garantizar un uso y una adopción responsables. Este análisis exhaustivo busca garantizar la transparencia total en torno a la metodología de prueba del modelo V8 de nuestro Detector de IA.
Fecha de la prueba: 15 de enero de 2025
Fecha de publicación: 18 de febrero de 2025
Modelo probado: V8
Los equipos de Ciencia de Datos y Control de Calidad de Copyleaks realizaron pruebas de forma independiente para garantizar resultados imparciales y precisos. Los datos de prueba diferían de los de entrenamiento y no contenían información enviada previamente al Detector de IA para su detección.
Los datos de prueba consistieron en texto escrito por humanos, procedente de conjuntos de datos verificados, y texto generado por IA a partir de diversos modelos de IA. La prueba se realizó con la API Copyleaks.
Las métricas incluyen la precisión general basada en la tasa de identificación de texto correcto e incorrecto, la puntuación F1, la tasa de verdaderos negativos (TNR), la tasa de verdaderos positivos (TPR), la precisión y las matrices de confusión.
Las pruebas verifican que el detector de IA muestra una alta precisión de detección para distinguir entre texto escrito por humanos y generado por IA, manteniendo una baja tasa de falsos positivos.
Proceso de evaluación
Mediante un sistema de dos departamentos, hemos diseñado nuestro proceso de evaluación para garantizar la máxima calidad, estándares y fiabilidad. Contamos con dos departamentos independientes que evalúan el modelo: el de ciencia de datos y el de control de calidad. Cada departamento trabaja de forma independiente con sus datos y herramientas de evaluación y no tiene acceso al proceso de evaluación del otro. Esta separación garantiza que los resultados de la evaluación sean imparciales, objetivos y precisos, a la vez que capturan todas las dimensiones posibles del rendimiento de nuestro modelo. Además, es fundamental tener en cuenta que los datos de prueba están separados de los de entrenamiento, y que solo probamos nuestros modelos con datos nuevos que no han visto anteriormente.
Metodología
Los equipos de control de calidad y ciencia de datos de Copyleaks recopilaron de forma independiente diversos conjuntos de datos de prueba. Cada conjunto de datos consta de un número finito de textos. La etiqueta esperada (un marcador que indica si un texto específico fue escrito por una persona o por una IA) de cada conjunto de datos se determina en función de la fuente de los datos. Los textos humanos se recopilaron de textos publicados antes del auge de los sistemas modernos de IA generativa o posteriormente de otras fuentes confiables que fueron verificadas nuevamente por el equipo. Los textos generados por IA se generaron utilizando diversos modelos y técnicas de IA generativa.
Las pruebas se realizaron con la API Copyleaks. Verificamos si la salida de la API era correcta para cada texto según la etiqueta de destino y, a continuación, agregamos las puntuaciones para calcular la matriz de confusión.
Resultados: Equipo de Ciencia de Datos
El equipo de Ciencia de Datos realizó la siguiente prueba independiente:
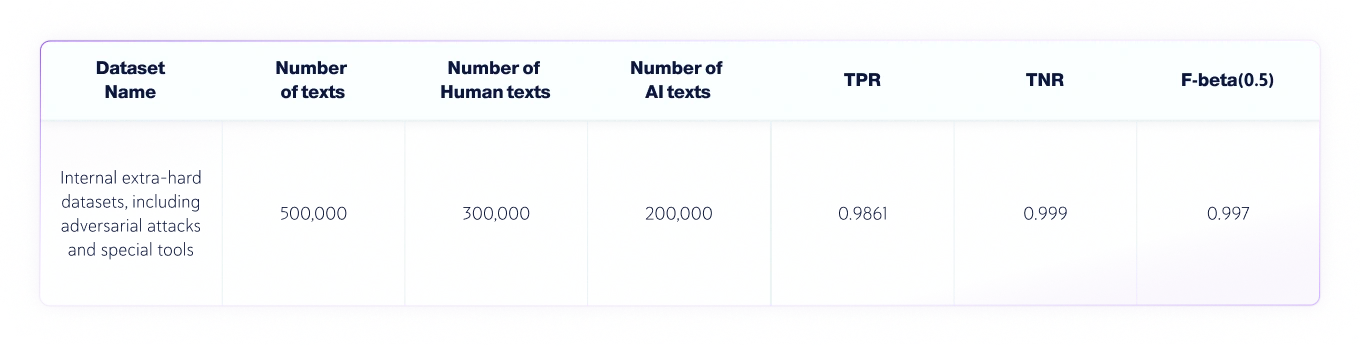
- El idioma de los textos era el inglés, y en total se probaron 300.000 textos escritos por humanos y 200.000 textos generados por IA de varios LLM..
- La longitud de los textos varía, pero los conjuntos de datos solo contienen textos con longitudes superiores a 350 caracteres, el mínimo que acepta nuestro producto.
Métricas de evaluación
Las métricas que se utilizan en esta tarea de clasificación de texto son:
1. Matriz de confusión: Tabla que muestra los TP (verdaderos positivos), FP (falsos positivos), TN (verdaderos negativos) y FN (falsos negativos).
2. Precisión: la proporción de resultados verdaderos (tanto verdaderos positivos como verdaderos negativos) entre el número total de textos que fueron comprobados.

3. TNR: La proporción de predicciones negativas precisas en todas las predicciones negativas.

En el contexto de la detección de IA, TNR es la precisión del modelo en textos humanos.
4. TPR (también conocido como Recall): La proporción de resultados positivos verdaderos en todas las predicciones reales.

En el contexto de la detección de IA, TPR es la precisión del modelo en los textos generados por IA.
5. Puntuación F-beta: La media armónica ponderada entre precisión y recuperación, favoreciendo más la precisión (ya que queremos favorecer una tasa de falsos positivos más baja).

Conjuntos de datos humanos e IA combinados
Resultados: Equipo de control de calidad
El equipo de control de calidad realizó la siguiente prueba independiente:
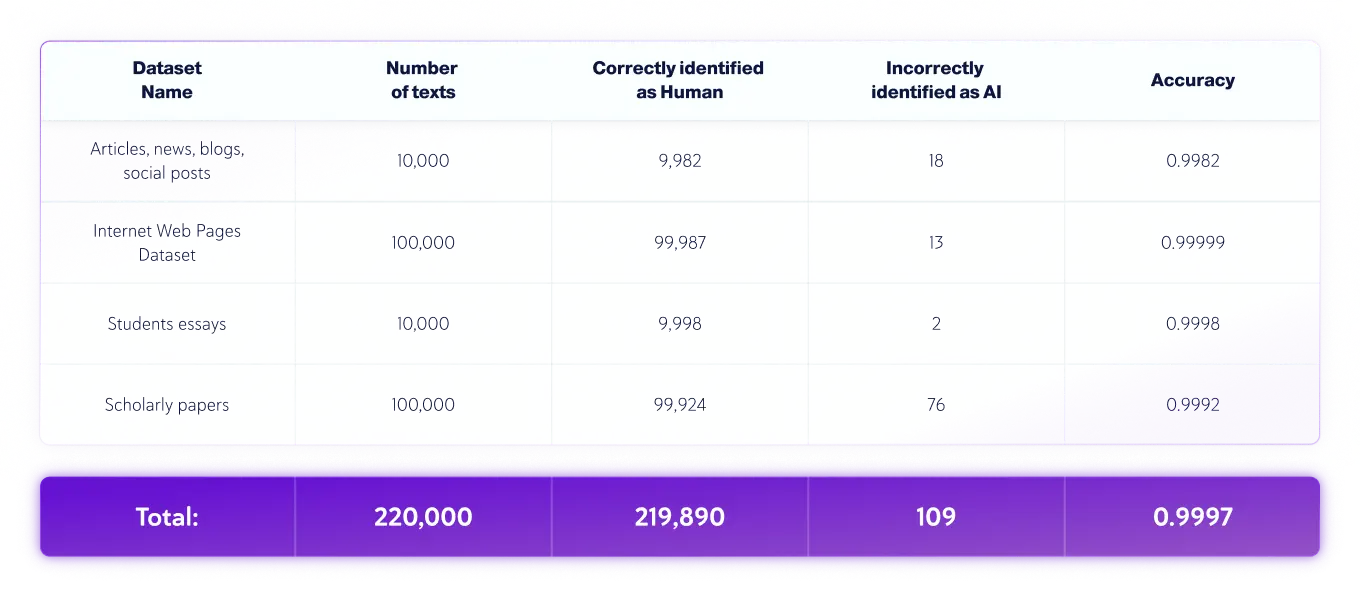
- El idioma de los textos era el inglés, y en total se probaron 220.000 textos escritos por humanos y 40.000 textos generados por IA de varios LLM..
- La longitud de los textos varía, pero los conjuntos de datos solo contienen textos con longitudes superiores a 350 caracteres, el mínimo que acepta nuestro producto.
Conjuntos de datos exclusivamente humanos
Conjuntos de datos solo de IA
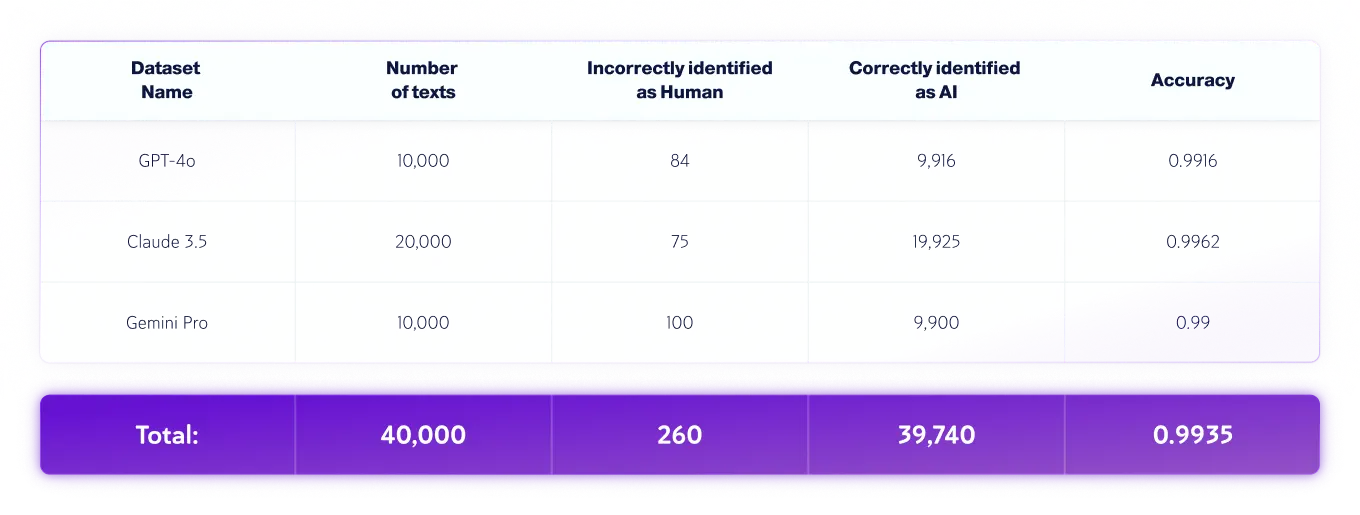
*Las versiones de los modelos pueden cambiar con el tiempo. Los textos se generaron utilizando una de las versiones disponibles de los modelos de IA generativa mencionados anteriormente.
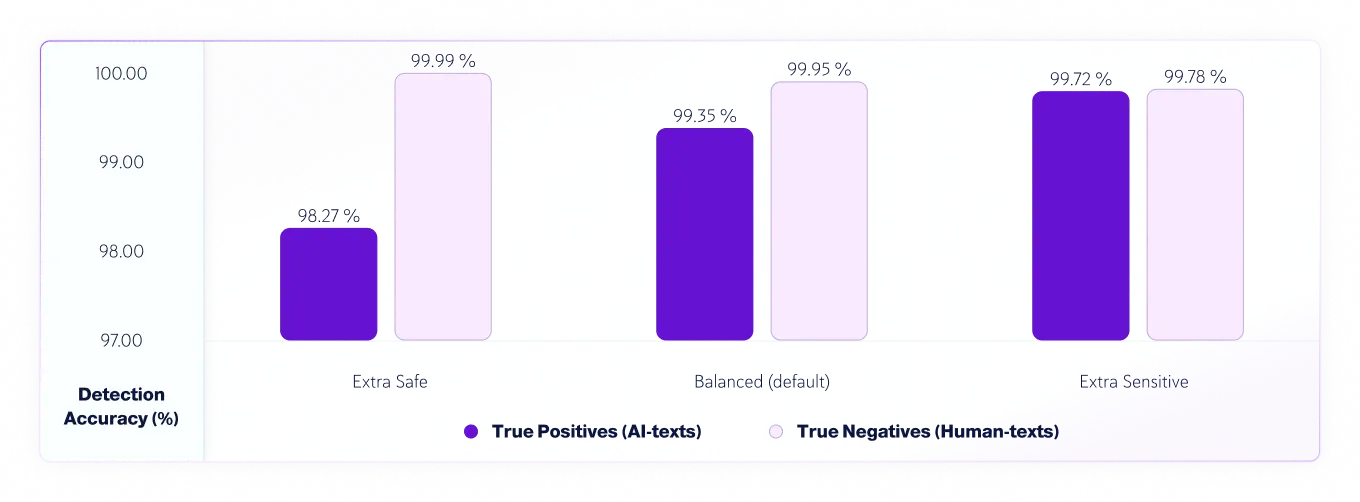
Niveles de sensibilidad
Desde la versión 7.1, contamos con tres niveles de sensibilidad para el modelo de detección de IA. Aquí están los resultados de las pruebas para los niveles de sensibilidad del modelo v8.
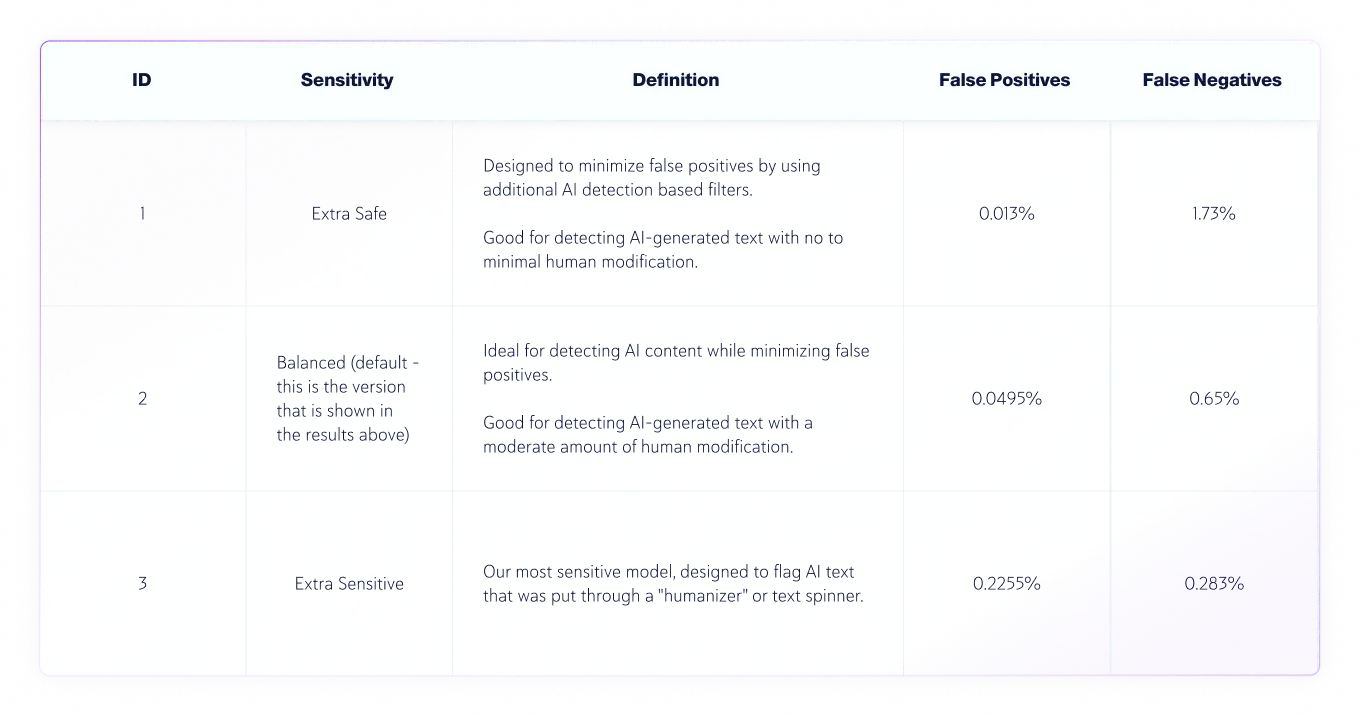
Precisión de verdaderos positivos (textos de IA) y verdaderos negativos (textos de humanos) por sensibilidad
Análisis de errores de texto humanos e IA
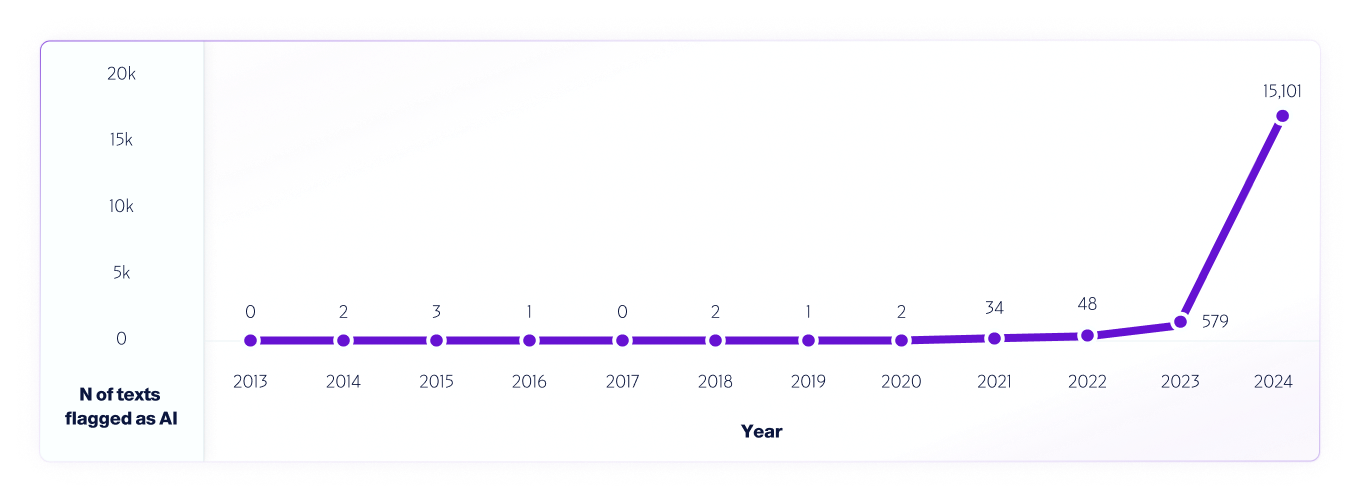
Durante el proceso de evaluación, identificamos y analizamos las evaluaciones incorrectas realizadas por el modelo y generamos un informe detallado que permitirá al equipo de ciencia de datos corregir las causas subyacentes. Esto se realiza sin exponer las evaluaciones incorrectas al equipo. Todos los errores se registran y categorizan sistemáticamente según su naturaleza en un proceso de análisis de causa raíz, cuyo objetivo es comprender las causas subyacentes e identificar patrones repetidos. Este proceso es continuo, lo que garantiza la mejora continua y la adaptabilidad de nuestro modelo a lo largo del tiempo.
Un ejemplo de este tipo de prueba es nuestro análisis Datos de internet de 2013 a 2024 con nuestro modelo V4. Tomamos muestras de un millón de textos de cada año, a partir de 2013, utilizando los falsos positivos detectados entre 2013 y 2020, antes del lanzamiento de los sistemas de IA, para mejorar aún más el modelo.
Similar a cómo investigadores de todo el mundo Hemos probado y continuamos probando diferentes plataformas de detectores de IA para evaluar sus capacidades y limitaciones. Animamos a nuestros usuarios a realizar pruebas en situaciones reales. A medida que se publiquen nuevos modelos, seguiremos compartiendo las metodologías de prueba, la precisión y otras consideraciones importantes a tener en cuenta.