Ressource
Évaluation de la précision du Copyleaks Détecteur IA
Une méthodologie étape par étape
Date du test : 15 janvier 2025
Date de publication : 18 février 2025
Modèle testé : V8
Nous pensons qu'il est plus important que jamais d'être totalement transparent sur les fonctionnalités du détecteur d'IA. Précision, taux de faux positifs et de faux négatifs, axes d'amélioration et autres informations pour garantir une utilisation et une adoption responsables. Cette analyse complète vise à garantir une transparence totale sur la méthodologie de test du modèle V8 de notre détecteur d'IA.
Les équipes de science des données et d'assurance qualité de Copyleaks ont effectué des tests de manière indépendante pour garantir des résultats impartiaux et précis. Les données de test différaient des données de formation et ne contenaient aucun contenu précédemment soumis au détecteur d'IA pour la détection d'IA.
Les données de test comprenaient du texte écrit par l'homme provenant d'ensembles de données vérifiés et du texte généré par l'IA à partir de divers modèles d'IA. Le test a été réalisé avec l'API Copyleaks.
Les mesures incluent la précision globale basée sur le taux d'identification de texte correct et incorrect, le score F1, le taux de vrais négatifs (TNR), le taux de vrais positifs (TPR), la précision et les matrices de confusion.
Les tests vérifient que le détecteur d’IA affiche une précision de détection élevée pour distinguer le texte écrit par l’homme du texte généré par l’IA tout en maintenant un faible taux de faux positifs.
Processus d'évaluation
Grâce à un système à deux départements, nous avons conçu notre processus d'évaluation pour garantir une qualité, des normes et une fiabilité optimales. Deux départements indépendants évaluent le modèle : l'équipe de science des données et l'équipe d'assurance qualité. Chaque département travaille indépendamment avec ses données et outils d'évaluation et n'a pas accès au processus d'évaluation de l'autre. Cette séparation garantit des résultats d'évaluation impartiaux, objectifs et précis, tout en capturant toutes les dimensions possibles de la performance de notre modèle. Il est également essentiel de noter que les données de test sont séparées des données d'entraînement, et que nous testons nos modèles uniquement sur de nouvelles données, inédites.
Méthodologie
Les équipes d'assurance qualité et de science des données de Copyleaks ont collecté indépendamment divers jeux de données de test. Chaque jeu de données est constitué d'un nombre fini de textes. L'étiquette attendue (un marqueur indiquant si un texte spécifique a été rédigé par un humain ou par une IA) de chaque jeu de données est déterminée en fonction de la source des données. Les textes humains ont été collectés à partir de textes publiés avant l'avènement des systèmes d'IA générative modernes ou ultérieurement par d'autres sources fiables, vérifiées à nouveau par l'équipe. Les textes générés par l'IA ont été générés à l'aide de divers modèles et techniques d'IA générative.
Les tests ont été exécutés avec l'API Copyleaks. Nous avons vérifié si le résultat de l'API était correct pour chaque texte en fonction de l'étiquette cible, puis nous avons agrégé les scores pour calculer la matrice de confusion.
Résultats : Équipe Data Science
L'équipe de science des données a réalisé le test indépendant suivant :
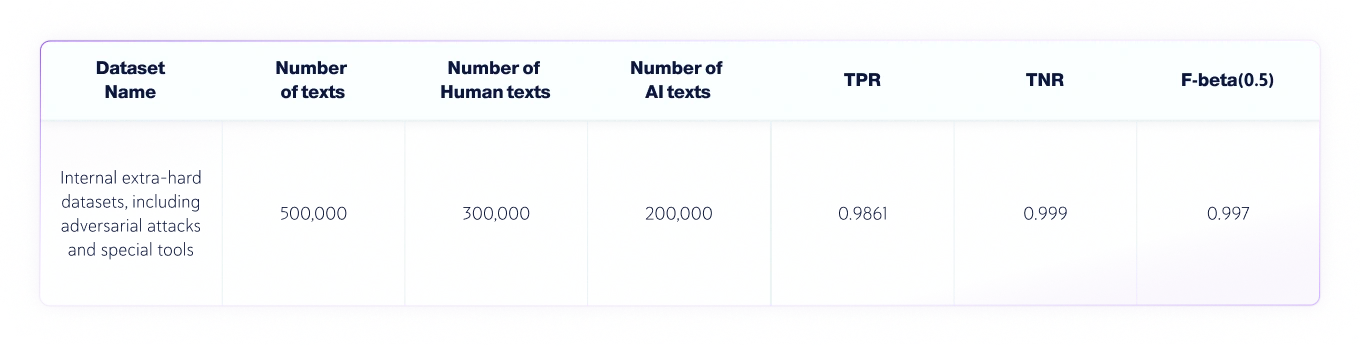
- La langue des textes était l'anglais, et 300 000 textes écrits par des humains et 200 000 textes générés par l'IA provenant de divers LLM ont été testés au total..
- La longueur des textes varie, mais les ensembles de données contiennent uniquement des textes d'une longueur supérieure à 350 caractères, le minimum accepté par notre produit.
Mesures d'évaluation
Les mesures utilisées dans cette tâche de classification de texte sont :
1. Matrice de confusion : Un tableau qui montre les TP (vrais positifs), les FP (faux positifs), les TN (vrais négatifs) et les FN (faux négatifs).
2. Précision : la proportion de vrais résultats (à la fois vrais positifs et vrais négatifs) parmi le nombre total de textes qui ont été vérifiés.

3. TNR : La proportion de prédictions négatives exactes dans toutes les prédictions négatives.

Dans le contexte de la détection de l'IA, le TNR est la précision du modèle sur les textes humains.
4. TPR (également connu sous le nom de rappel) : la proportion de vrais résultats positifs dans toutes les prédictions réelles.

Dans le contexte de la détection de l'IA, le TPR est la précision du modèle sur les textes générés par l'IA.
5. Score F-bêta : Le moyenne harmonique pondérée entre précision et rappel, privilégiant davantage la précision (car nous souhaitons favoriser un taux de faux positifs plus faible).

Ensembles de données combinées IA et humaines
Résultats : équipe d'assurance qualité
L'équipe d'assurance qualité a effectué le test indépendant suivant :
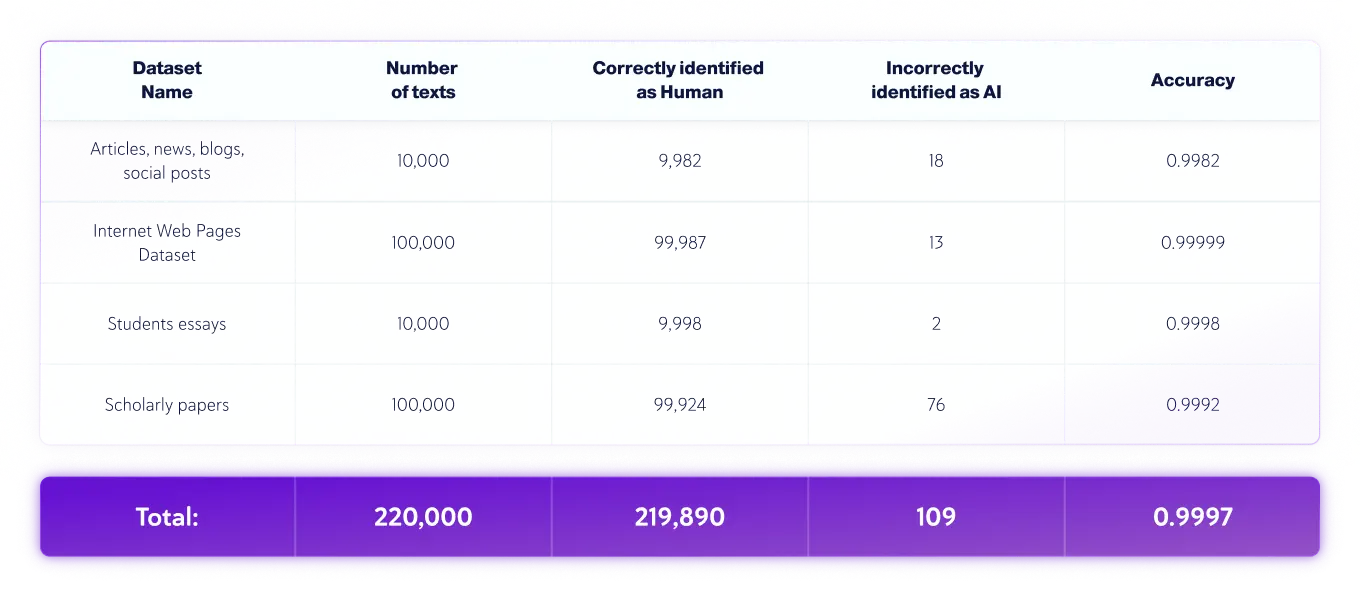
- La langue des textes était l'anglais, et 220 000 textes écrits par des humains et 40 000 textes générés par l'IA provenant de divers LLM ont été testés au total..
- La longueur des textes varie, mais les ensembles de données contiennent uniquement des textes d'une longueur supérieure à 350 caractères, le minimum accepté par notre produit.
Ensembles de données réservés aux humains
Ensembles de données réservés à l'IA
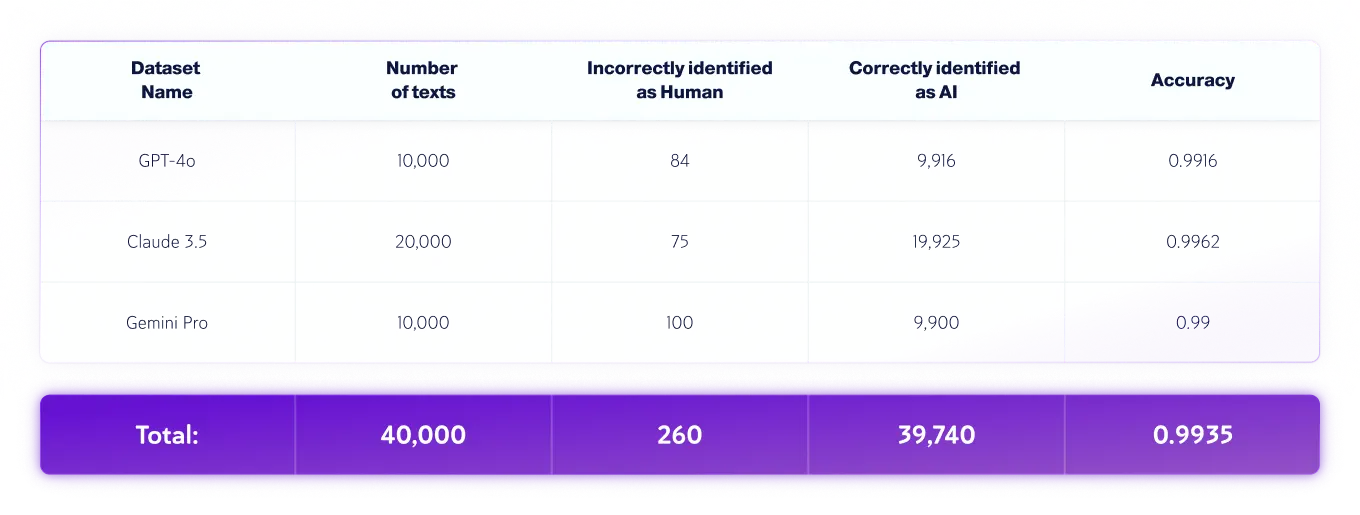
*Les versions des modèles peuvent changer au fil du temps. Les textes ont été générés à l'aide de l'une des versions disponibles des modèles d'IA génératifs ci-dessus.
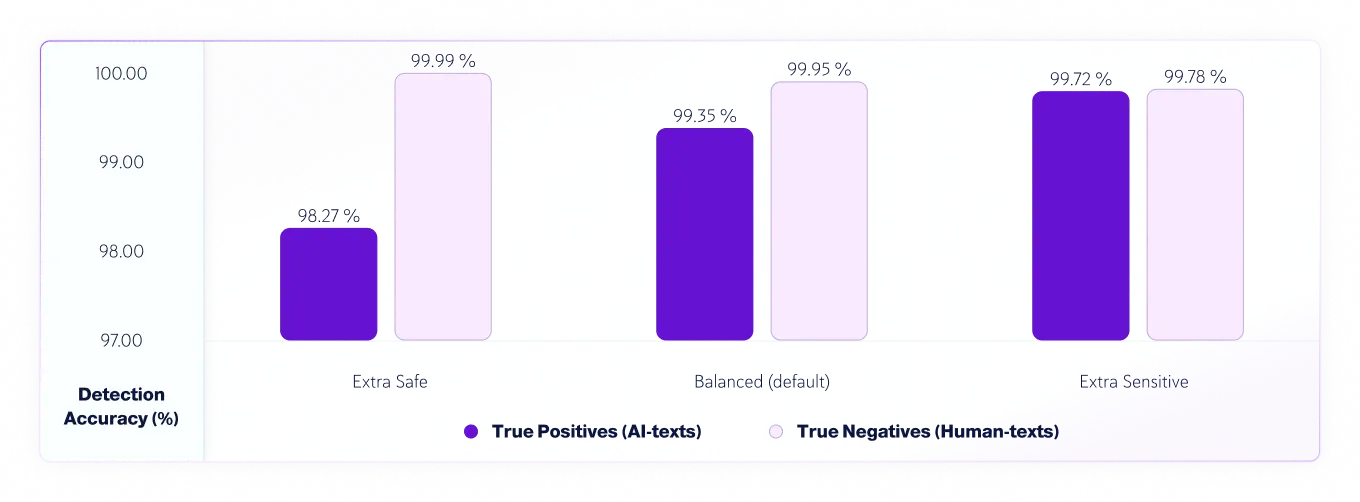
Niveaux de sensibilité
Depuis la version 7.1, nous disposons de trois niveaux de sensibilité pour le modèle de détection IA. Voici les résultats des tests pour les niveaux de sensibilité du modèle v8.
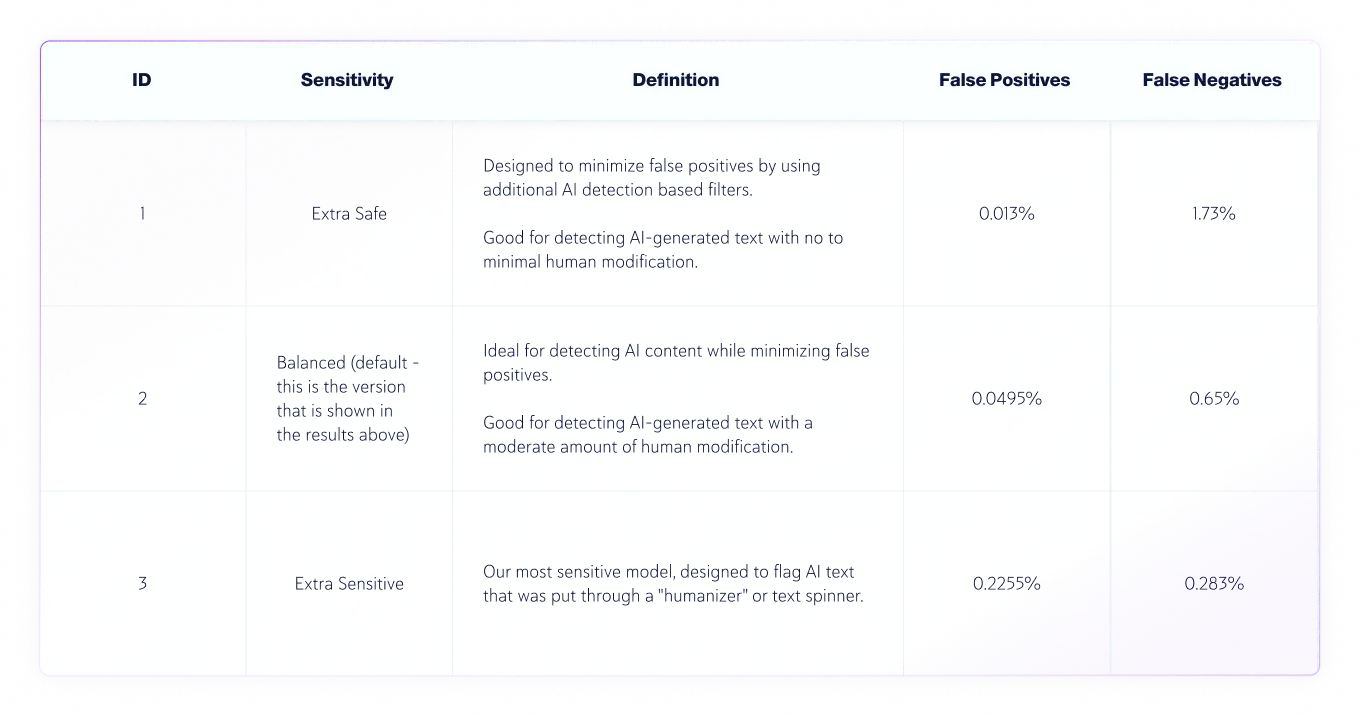
Précision des vrais positifs (textes IA) et des vrais négatifs (textes humains) par sensibilité
Analyse des erreurs de texte par l'homme et l'IA
Au cours du processus d'évaluation, nous avons identifié et analysé les erreurs d'évaluation du modèle et créé un rapport détaillé qui permettra à l'équipe de science des données de corriger les causes sous-jacentes. Cette opération se fait sans que les erreurs soient révélées à l'équipe de science des données. Toutes les erreurs sont systématiquement enregistrées et catégorisées selon leur nature dans le cadre d'une analyse des causes profondes, visant à comprendre les causes sous-jacentes et à identifier les schémas récurrents. Ce processus est permanent, garantissant l'amélioration continue et l'adaptabilité de notre modèle au fil du temps.
Un exemple d’un tel test est notre analyse de données Internet de 2013 à 2024 à l'aide de notre modèle V4. Nous avons échantillonné 1 million de textes par année, à partir de 2013, en utilisant les faux positifs détectés entre 2013 et 2020, avant la sortie des systèmes d'IA, afin d'améliorer encore le modèle.
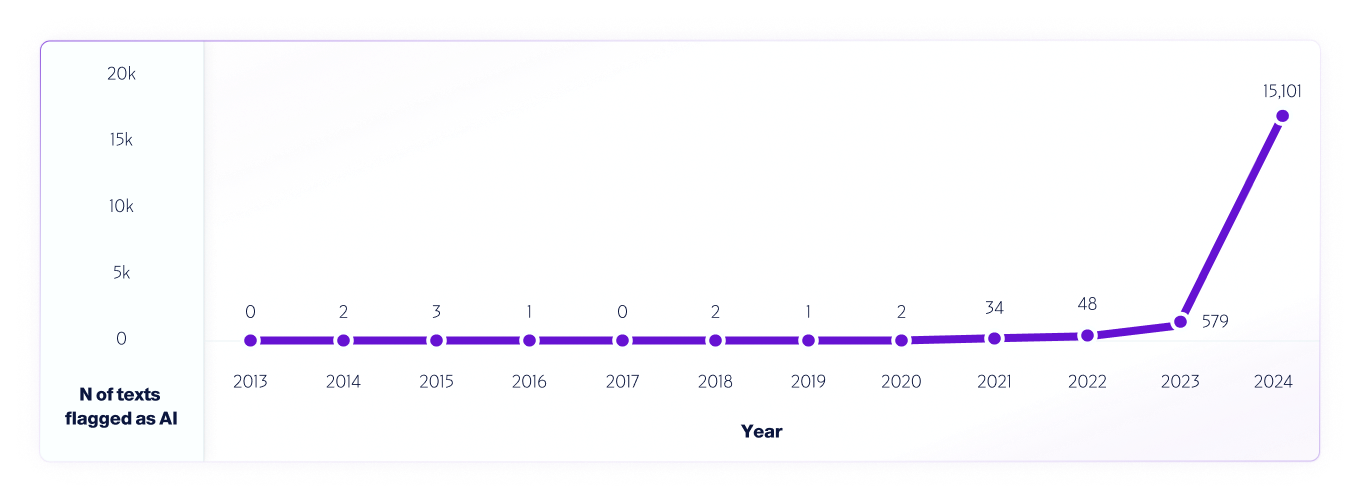
Similaire à la façon dont chercheurs du monde entier Nous avons testé et continuons de tester différentes plateformes de détection d'IA pour évaluer leurs capacités et leurs limites. Nous encourageons donc vivement nos utilisateurs à effectuer des tests en conditions réelles. En fin de compte, à mesure que de nouveaux modèles seront commercialisés, nous continuerons de partager les méthodologies de test, la précision et d'autres considérations importantes à prendre en compte.