Recurso
Avaliando a precisão do Copyleaks Detector de IA
Uma Metodologia Passo a Passo
Data do teste: 15 de janeiro de 2025
Data de publicação: 18 de fevereiro de 2025
Modelo testado: V8
Acreditamos que é mais importante do que nunca ser totalmente transparente sobre o Detector de IA precisão, as taxas de falsos positivos e falsos negativos, áreas para melhoria e mais para garantir o uso e a adoção responsáveis. Esta análise abrangente visa garantir total transparência em torno da metodologia de teste do modelo V8 do nosso Detector de IA.
As equipes de Ciência de Dados e QA do Copyleaks realizaram testes de forma independente para garantir resultados imparciais e precisos. Os dados de teste diferiam dos dados de treinamento e não continham conteúdo previamente enviado ao Detector de IA para detecção de IA.
Os dados de teste consistiram em texto escrito por humanos originados de conjuntos de dados verificados e texto gerado por IA de vários modelos de IA. O teste foi realizado com a API Copyleaks.
As métricas incluem precisão geral com base na taxa de identificação de texto correto e incorreto, pontuação F1, taxa de verdadeiro negativo (TNR), taxa de verdadeiro positivo (TPR), precisão e matrizes de confusão.
Os testes verificam se o Detector de IA exibe alta precisão de detecção para distinguir entre texto escrito por humanos e gerado por IA, mantendo uma baixa taxa de falsos positivos.
Processo de avaliação
Usando um sistema de departamento duplo, projetamos nosso processo de avaliação para garantir qualidade, padrões e confiabilidade de alto nível. Temos dois departamentos independentes avaliando o modelo: as equipes de ciência de dados e QA. Cada departamento trabalha de forma independente com seus dados e ferramentas de avaliação e não tem acesso ao processo de avaliação do outro. Essa separação garante que os resultados da avaliação sejam imparciais, objetivos e precisos, ao mesmo tempo em que capturam todas as dimensões possíveis do desempenho do nosso modelo. Além disso, é essencial observar que os dados de teste são separados dos dados de treinamento, e testamos nossos modelos apenas em novos dados que eles não viram no passado.
Metodologia
As equipes de QA e Ciência de Dados da Copyleaks reuniram de forma independente uma variedade de conjuntos de dados de teste. Cada conjunto de dados de teste consiste em um número finito de textos. O rótulo esperado — um marcador que indica se um texto específico foi escrito por um humano ou por IA — de cada conjunto de dados é determinado com base na fonte dos dados. Textos humanos foram coletados de textos publicados antes do surgimento dos modernos sistemas de IA generativa ou posteriormente por outras fontes confiáveis que foram verificadas novamente pela equipe. Textos gerados por IA foram gerados usando uma variedade de modelos e técnicas de IA generativa.
Os testes foram executados contra a API Copyleaks. Verificamos se a saída da API estava correta para cada texto com base no rótulo de destino e, em seguida, agregamos as pontuações para calcular a matriz de confusão.
Resultados: Equipe de Ciência de Dados
A equipe de Ciência de Dados conduziu o seguinte teste independente:
- O idioma dos textos era o inglês, e 300.000 textos escritos por humanos e 200.000 textos gerados por IA de vários LLMs foram testados no total.
- Os comprimentos dos textos variam, mas os conjuntos de dados contêm apenas textos com comprimentos maiores que 350 caracteres, o mínimo que nosso produto aceita.
Métricas de avaliação
As métricas usadas nesta tarefa de classificação de texto são:
1. Matriz de confusão: Tabela que mostra os TP (verdadeiros positivos), FP (falsos positivos), TN (verdadeiros negativos) e FN (falsos negativos).
2. Precisão: a proporção de resultados verdadeiros (tanto verdadeiros positivos quanto verdadeiros negativos) entre o número total de textos que foram verificados.

3. TNR: A proporção de previsões negativas precisas em todas as previsões negativas.

No contexto da detecção de IA, o TNR é a precisão do modelo em textos humanos.
4. TPR (também conhecido como Recall): A proporção de resultados positivos verdadeiros em todas as previsões reais.

No contexto da detecção de IA, TPR é a precisão do modelo em textos gerados por IA.
5. Pontuação F-beta: A média harmônica ponderada entre precisão e recall, favorecendo mais a precisão (pois queremos favorecer uma menor Taxa de Falso Positivo).

Conjuntos de dados combinados de IA e humanos
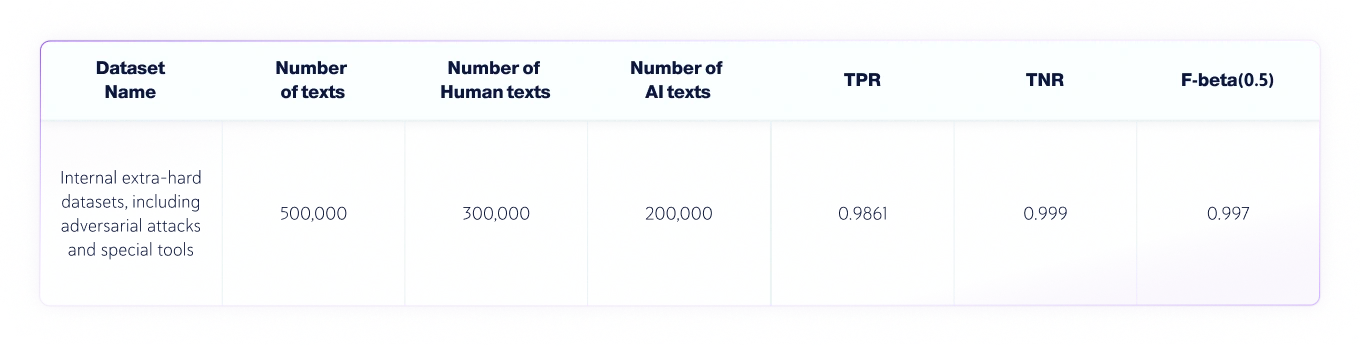
Resultados: Equipe de QA
A equipe de controle de qualidade conduziu o seguinte teste independente:
- O idioma dos textos era o inglês, e 220.000 textos escritos por humanos e 40.000 textos gerados por IA de vários LLMs foram testados no total.
- Os comprimentos dos textos variam, mas os conjuntos de dados contêm apenas textos com comprimentos maiores que 350 caracteres, o mínimo que nosso produto aceita.
Conjuntos de dados somente para humanos
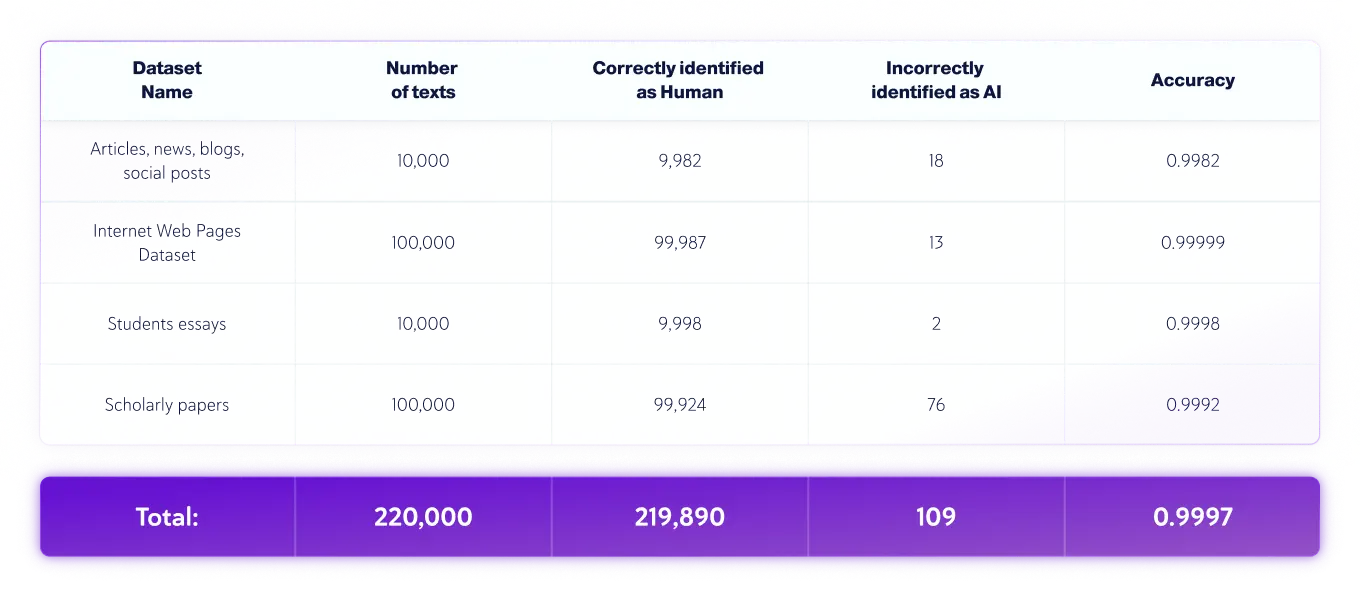
Conjuntos de dados somente para IA
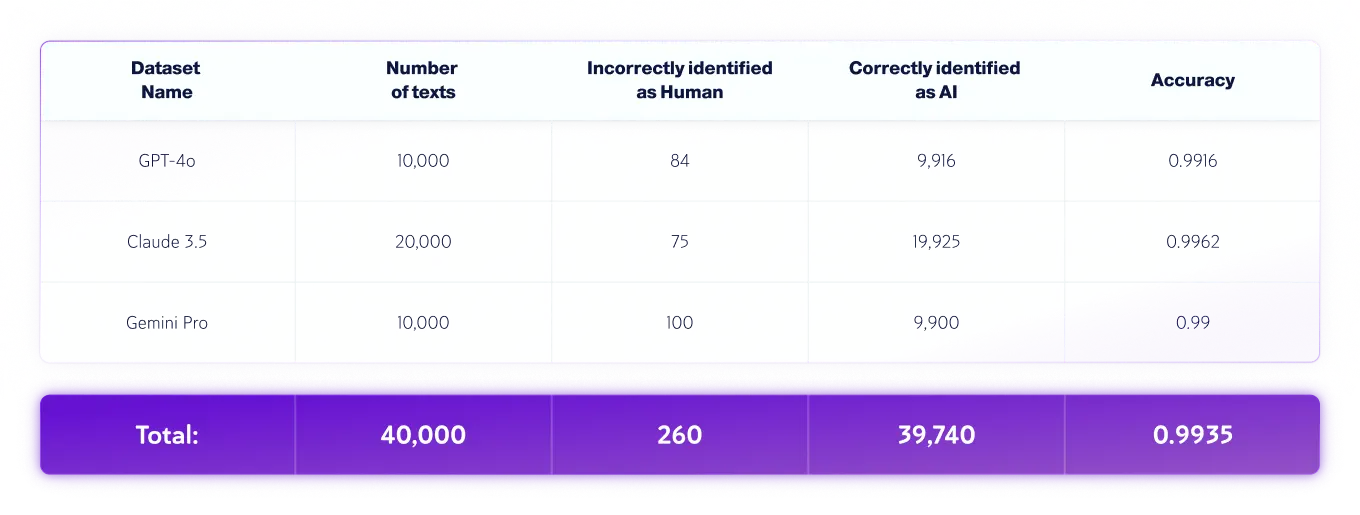
*As versões do modelo podem mudar ao longo do tempo. Os textos foram gerados usando uma das versões disponíveis dos modelos de IA generativos acima.
Níveis de sensibilidade
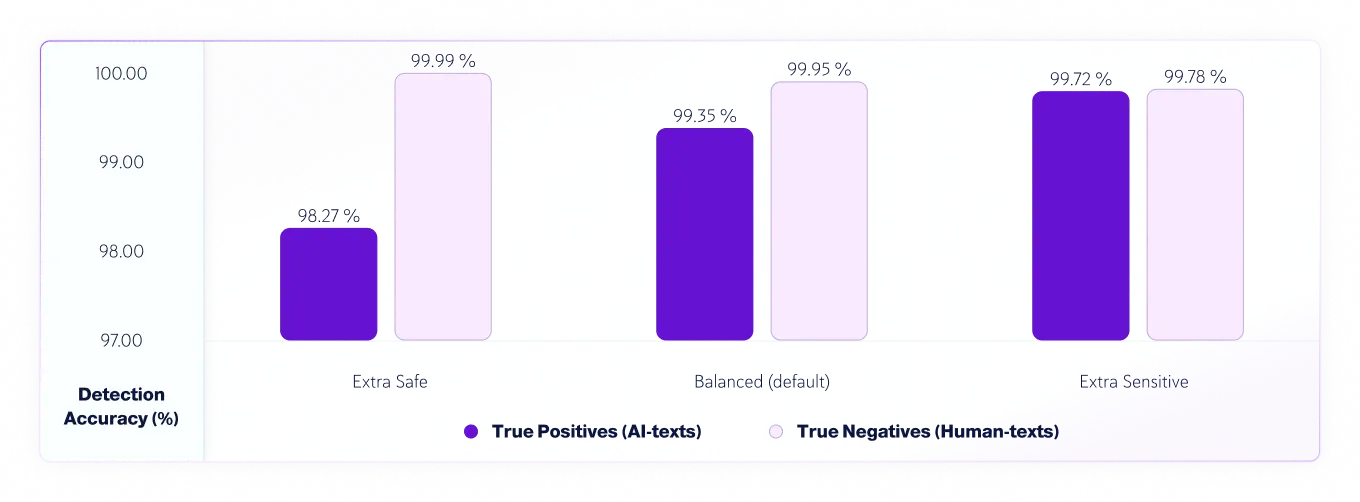
Desde a v7.1, temos 3 níveis de sensibilidade para o modelo de detecção de IA. Aqui estão os resultados dos testes para os níveis de sensibilidade do modelo v8.
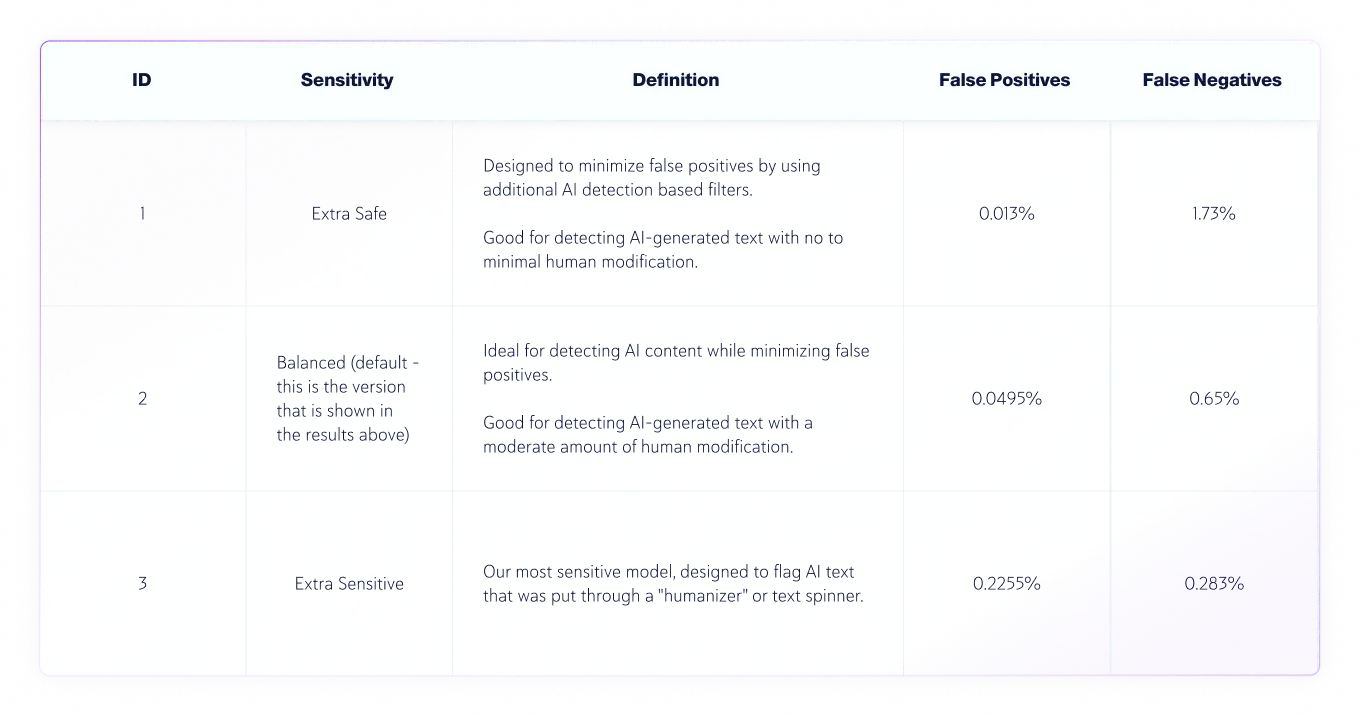
Precisão de Verdadeiros Positivos (textos de IA) e Verdadeiros Negativos (textos humanos) por Sensibilidade
Análise de erros de texto humanos e de IA
Durante o processo de avaliação, identificamos e analisamos avaliações incorretas feitas pelo modelo e criamos um relatório detalhado que permitirá que a equipe de ciência de dados corrija as causas subjacentes. Isso é feito sem expor as avaliações incorretas à equipe de ciência de dados. Todos os erros são sistematicamente registrados e categorizados com base em seu caráter e natureza em um “processo de análise de causa raiz”, que visa entender as causas subjacentes e identificar padrões repetidos. Esse processo é sempre contínuo, garantindo melhoria contínua e adaptabilidade do nosso modelo ao longo do tempo.
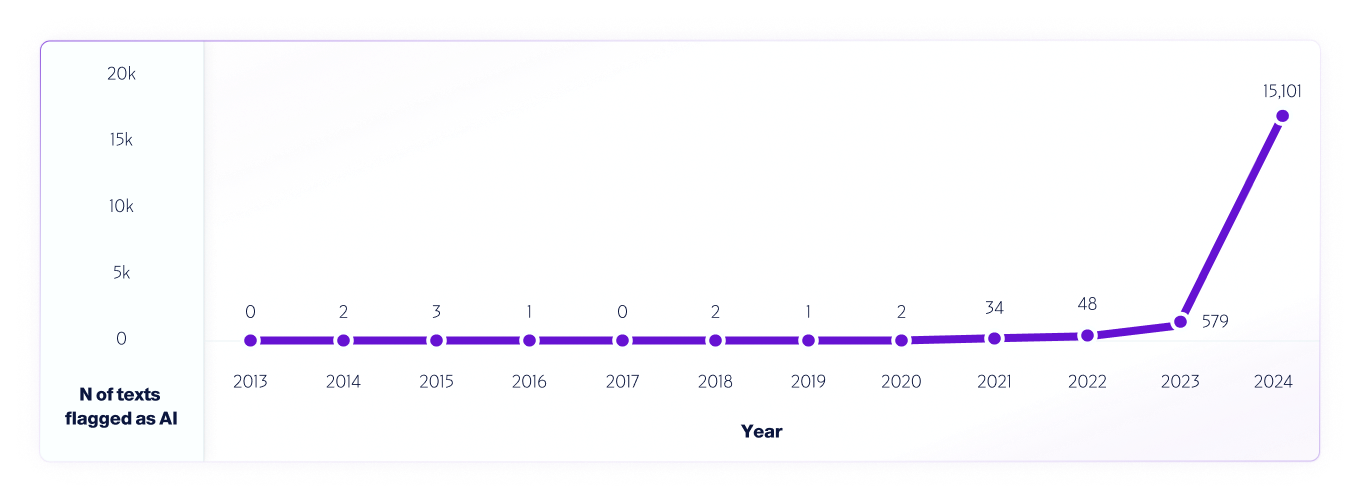
Um exemplo de tal teste é nossa análise de dados da internet de 2013 a 2024 usando nosso modelo V4. Amostramos 1 milhão de textos de cada ano, começando em 2013, usando quaisquer falsos positivos detectados de 2013 a 2020, antes do lançamento dos sistemas de IA, para ajudar a melhorar ainda mais o modelo.
Semelhante a como pesquisadores em todo o mundo temos e continuamos a testar diferentes plataformas de detectores de IA para avaliar suas capacidades e limitações, encorajamos totalmente nossos usuários a conduzir testes no mundo real. Por fim, conforme novos modelos forem lançados, continuaremos a compartilhar as metodologias de teste, precisão e outras considerações importantes a serem observadas.